GraphQL is a technology I’ve long been a sceptic of. But I’ve finally seen the light. Now, I firmly believe that the future is a graph. Let me explain why.
Let’s first look at a few home truths about complex systems:
- A system’s complexity will grow as the size of the organisation grows.
- Well-sized, smaller systems are easier to manage than massive monoliths.
- The modern organisation is not just about the software it builds, but also the software it uses.
These points reflect the reality that software is all around us. Software is delivered as an API not just to consumers via apps and sites; it forms a full-blown architectural pattern.
Microservices: Well-sized services, not monoliths
You probably know where this is going: microservices!
Let’s use a better term: well-sized services. I don’t want to get into a debate about how big or small the domain of a service should be. Let’s just agree on the underlying principle that smaller, well-defined units are easier to manage than large, singular ones.
You could say that a well-built monolith, one that takes its SOLID principles seriously, and tries to operate a DRY development ethos, is essentially in the same boat as a big microservice application. And you’d be correct – to a point.
For one thing, the fact that using a monorepo from a microservices stack is a popular decision is telling. But there’s a bit more to it than that.
Microservice architectures are most beneficial to the ops and software development lifecycle teams. They need to coordinate releases and manage the cost of scale. It’s a layer above the build itself where microservices really shine. Inevitably, breaking up a monolith does make sense for larger organisations.
Of course, the other benefit is speed to market. Making changes to a microservice is like hot-swapping code, which is a good thing. The thing is, this doesn’t reflect the whole picture of an API-first organisation.
Legacy spaghetti
I don’t want to wax lyrical about why microservices have come to be so dominant in today’s enterprises. Instead, I’d like to talk about all the other services that inexorably become part of your services ecosystem without you asking for it.
Here’s a stat that sheds some light: the average organisation will have up to 137 different SaaS applications that it uses to operate the business. We’re talking CRM, identities, stock management, eCommerce, newsletters, human resources, recruitment, advertising… and there are thousands more I haven’t even mentioned here.
It’s extremely likely that you’re constantly interacting with the APIs from these services. For example, getting a notification from Slack whenever a contact form has been submitted, or when a sale has been completed.
When you buy any SaaS service, a key feature that should be on offer is an API. Almost all of these products do have one, to an extent. The question is, do you really use them?
Think about how much value is trapped inside the data silos that these applications aggregate. They store information from software interactions, as well as human interactions. Their inputs are from your staff, every day, all the time. They provide you with information about the real world that can be categorised and filtered.
This isn’t a new problem. Back in the 90s, you’d buy an Oracle database and host it yourself, or you’d buy a SharePoint or WebSphere system and run it on dedicated hardware.
Then along came the cloud. You can migrate it out and save on hardware. But you’re still dealing with this massive store of value.
Enter lovely APIs
Nowadays, instead of an isolated silo, you now have these lovely APIs to interact with.
If you follow the trends, you’ll know that all of these older, self-hosted and licensed solutions are moving to more profitable and agile pay-as-you-go solutions. They sit in infrastructure that you don’t need to maintain or patch.
We integrate with these silos all the time. It’s one of the key drivers of the software industry. Many of us have to integrate with Stripe, with PayPal, with Twilio…
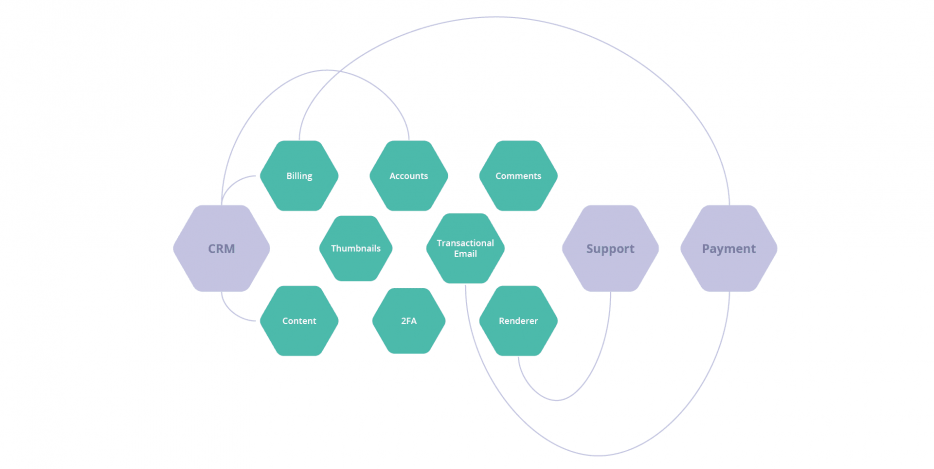
The thing is, those integrations are a bit messy. A typical integration has a series of microservices that consume dependent external APIs. It’s a point-to-point integration. There’s nothing wrong with the approach, especially from an “outside in” perspective. The application stack consumes data, and calls functions from the dependencies.
One thing worth mentioning here is that the more of your services that interact with a dependency, the more risk you have. Of course, using SOLID principles, we can avoid that with the façade pattern. In this case, we only need to update the façades if a vendor decides to give us grief with an unannounced upgrade or a breaking change.
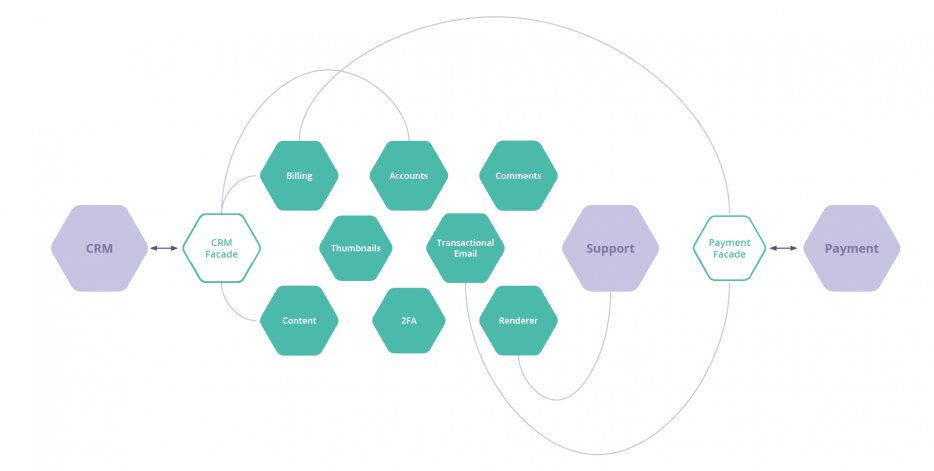
But we’ve now added two more services – and those services will have multiple dependents. So, a single failure now affects multiple interlocked services. They’re entangled. It’s a slightly different matter when you need, for example, the support system to speak to the CRM system as well.
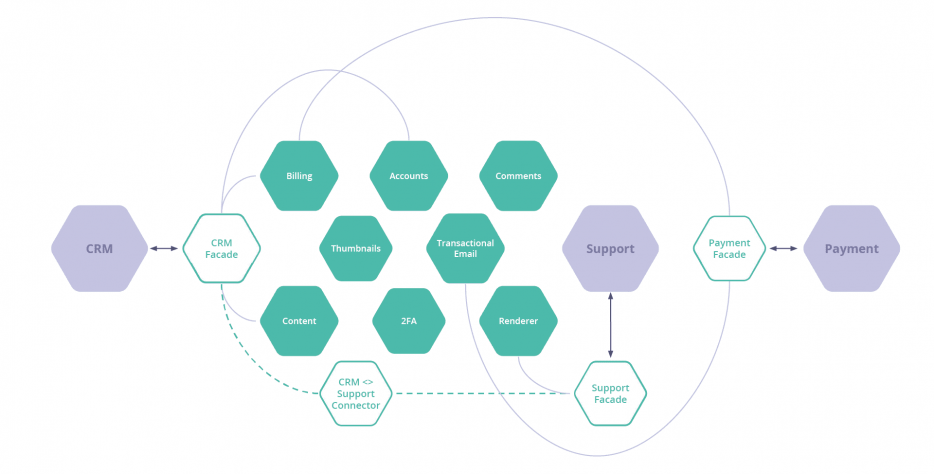
Sorry, brains
If your brain is hurting at this point – it should be! This is how you end up with microservices bloat. I won’t side-track into service mesh at this point, but I will say that a service mesh will NOT save you here. It just makes the diagram look cleaner. Under the hood, these are still point-to-point integrations with a mediator.
To get the CRM system to talk to the support system, you have to do two things:
- You have to build a new façade, because the number of dependencies goes above one.
- You also have to write a connector service to normalise the data between the two systems.
So you end up with a custom connector you’ve built. It might just be a lambda function. Nonetheless, it’s more bloat that you need to maintain.
The big picture
In summary:
- You need to write multiple new services to properly abstract external dependencies.
- Should you wish to directly integrate two dependencies, you need to write a mediator service.
- All of this is somewhat mediated by a service mesh, but that also means that you now need to manage a service mesh, and the integrations are still point-to-point.
- If you wish to perform an integration with a dependency of another service, you need to integrate with the façade…
- ….and if the façade doesn’t encompass the full functionality of the dependency, you need to modify the façade as well.
It’s that last point that’s probably the biggest issue. Ideally, when writing software – especially microservices – you want to keep the functional footprint (and therefore risk) as small as possible. You only ever build exactly what you need.
This isn’t a bad approach – IF you have the liberty of a homogenous, well-crafted, perfectly-executed microservice. Service mesh stacks, in reality, are a whole lot more messy.
The traditional approach
There’s a more traditional way to deal with this: It’s one that some organisations might deploy already. It’s one that – in theory – shouldn’t require more code and potentially could solve the façade functionality problem.
The solution is called: “throw money at it!”
In this scenario, somebody like me comes along and tells you that you need to install an ETL system to normalise and combine all your data. You’ll need to wire into the data warehousing platform that you’ve been querying with your business intelligence software.
Then you’ll need to install an enterprise service bus because it can provide normalisation connectors for the APIs of each of your dependencies – for a price!
And then, you’ll have to modify your microservices to account for the message-based development pattern needed to get all of it working.
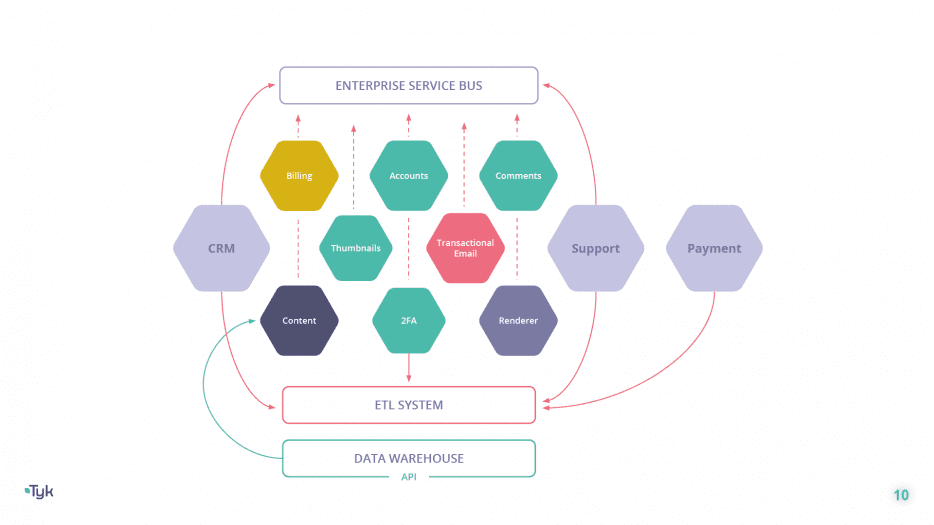
All of a sudden, your complexity has tripled. You have new inputs, new outputs, and a new integration challenge that’s meant to handle your existing integration challenge!
Of course, this is an extreme example. You may not need all of these things – you may only need one or two. Unfortunately, even just one of these solutions adds significant system complexity – and you deserve better!
Doing more with microservices
So, ask yourself, “surely I can do more with my microservices? It looks manageable. Why add more layers of software co-ordination to connect stuff when I can just write a microservice and do it myself?”
What IS a modern, microservice-addicted organisation meant to do with their 137 SaaS applications – applications that potentially enrich and store massive amounts of value and data about their operations?
The answer is NOT to lash it all together with intermediary microservices, as tempting as that may be to scratch the short-term itch.
As we’ve demonstrated, it’s a great deal of work and you still have the scope challenge to contend with to mitigate future integrations. It also means that you need to build an API observance team to keep up with any and all dependent changes on the upstream.
That would suck, right? Imagine having to maintain and manage someone else’s API? Who in their right mind would ever want to do API management for a living?!
Stepping into the present
Let’s look at a different paradigm:
- What if you could integrate your data as easily as a database table join?
- What if you had a data integration layer, and never had to change your upstream services?
- What if, when you needed to integrate your CRM platform with your accounts microservice, you didn’t need to write a new layer, or make a point-to-point integration?
- What if you exchanged your message bus for an API bus?
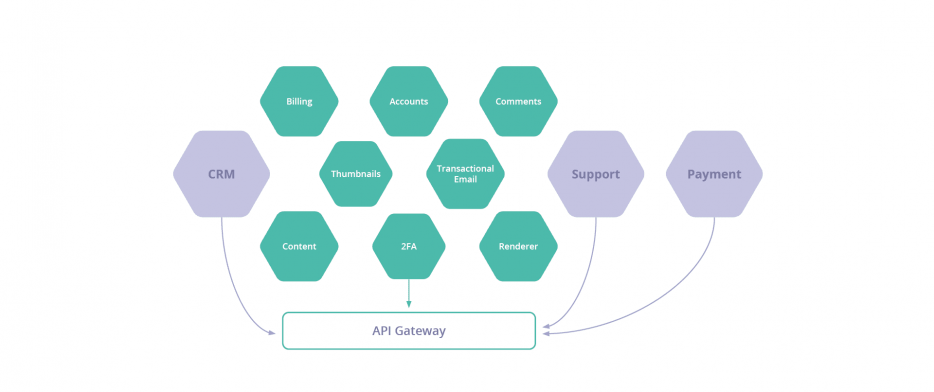
If you’re using microservices, you are very likely to be using an API gateway. So why not just do the integration there?
Well, as much as we would love everyone to use their API gateway to do integration, that is NOT the way. As soon as you do that, your API gateway becomes your new monolith. Why? Because you likely need to pack a bunch of business logic into the gateway. And that’s a hidden complexity; the code and the logic are no longer directly part of your software cycle – so you may as well have written a bunch of intermediary services.
Ultimately, you are also dealing with the raw APIs of your SaaS providers. So you’re still doing point-to-point integrations, and baking vendor logic (and potentially even SDKs) into your application layer.
You need something better. And this is where, in Tyk’s opinion, GraphQL really shines.
Hello, GraphQL
GraphQL is hot, but for all the wrong reasons. Most proponents will argue that it increases the speed to market of an API client application, such as a single page app or mobile app. This is true… until the point where you dig a little deeper into the paradigm.
The key issue with GraphQL, as an externally focused interface, is that it exposes you to risks:
- You cannot easily predict the paths a query will take.
- You need to think about deeply nested queries that could potentially cause a Denial of Service attack.
- You need to worry about accidentally exposing data that you really don’t want to.
Securing GraphQL is still an open subject (by the way, Tyk does a great job of it!). All the freedom of getting what you want, when you want, how you want, also means exposing all the options to do so to a client app.
And here’s the kicker: it’s a single-page app that you do not control.
Let’s take a step back…
GraphQL shines when considered in the internal API or integration context. Why is that?
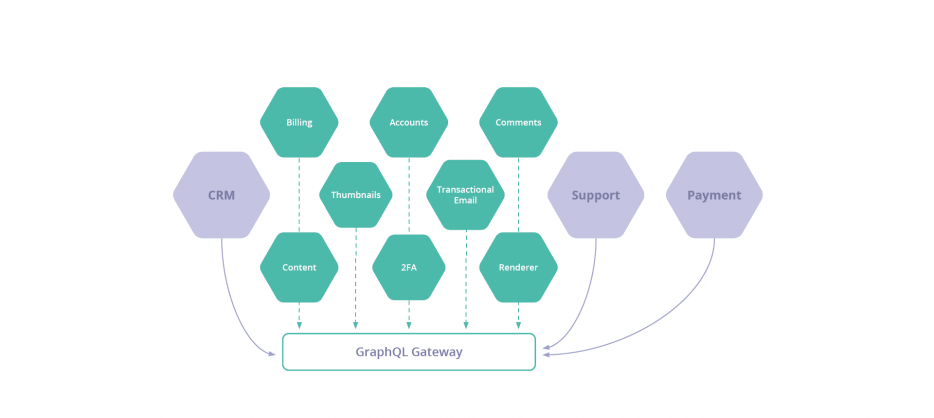
Well, GraphQL is a structured query language – one that gives you what you want, when you want, and how you want it.
Say all of your internal services were GraphQL, and you wrote resolvers for all of your 137 third-party SaaS APIs. You could then – theoretically – query any data in your stack with a single query language and get a normalised response back.
This is not dissimilar to the earlier example of writing intermediary services. What we are suggesting is that GraphQL should really be considered as an extremely powerful integration language layer, because it has all the hallmarks you need:
- It normalises data for the request to JSON, specified by the GraphQL schema, which is strongly typed.
- Mediation happens in the resolver.
- It provides a standard interface to interact with multiple services, normalising the client code significantly.
- It can handle (but does not rely on) message queues and real-time event subscriptions, making it an optional component that can still deliver message-based or active pipelines.
- With good resolvers, it’s possible to stitch data together between schemas, and therefore create a single graph, with the entire service interdependency stack.

Huzzah! Well, theoretically…
If you built your APIs graph-first, then you could create an enterprise-wide data plane that can be queried by any developer for any imaginable integration requirement.
In the world of microservices, lambda functions and service meshes, having a standardised interface to all your data means mediating operations between applications suddenly becomes extremely easy.
- No more proprietary connectors.
- Fewer concerns around compatibility and upgrades for systems.
- No more reliance on a message bus and its associated architecture.
- A self-describing, discoverable unified query language for all your data.
- A new focus on function, not data.
- Faster dependency consumption, giving you a faster time to market.
This really is APIs all the way down. But before the angry comments start flowing, I have glossed over a few things.
Ironing out the wrinkles
There are still some real problems to solve with this idea. GraphQL, as it stands now, is only suitable if used in a greenfield context – with new applications. You can write your services in GraphQL first, and not need to write middleware resolvers for a pre-existing REST or gRPC service stack.
You don’t want APIs on APIs.
And, truly, it’s only really useful if your SaaS service providers themselves provide a GraphQL API. Otherwise you need to write a specific resolver for them, and maintain it. Then, we’re back to the same problem we had with our API gateway bus.
Last but not least: in the end, in order to perform some integrations, you’ll still need to write new logic for services to handle complex edge cases.
So maybe we haven’t quite reached an API first integration panacea… yet.
The future is a graph
At Tyk we’re spending a lot of time on this problem. We’re pretty convinced that APIs are the integration paradigm of the future. And we believe that GraphQL is a fertile ground on which to plant the seeds for this new way of thinking about service integration.
If you could achieve a GraphQL data layer to handle your integration and plug in all of your external and internal data sources – with a single query language for all of your company’s data – it would be insanely powerful.

That’s why we’ve spent the last two years trying to make this a reality. We call it the Universal Data Graph and it’s an engine that enables you to do exactly what’s described here – without having to write new resolvers or code at all. Tyk does all that for you.
Modern enterprises that are trying to liberate their data silos with their microservice stack should take a close look at GraphQL as an equaliser.
I believe there’s a significant future ahead for GraphQL – not as a consumer-facing API paradigm, but one that offers incredible opportunities as a discoverable, easy-to-use, highly visible integration platform.
More importantly, it’s intrinsically compatible with the API-first reality that we find ourselves in today.
