Sizing your infrastructure is part science and part optimism. Being sure that it is sized to enable growth, while also keeping down costs, is a challenge that all organisations go through.
Helpfully, you can use a careful analysis of system metrics to determine what your baseline needs will be. This can include factors like how many requests per second you expect or receive, what your consumers’ tolerance is for latency, and how deeply you need to look at fault tolerance. This approach covers the scientific side of the equation.
The optimistic side of the infrastructure sizing equation asks how much demand your users will put on your infrastructure in the future. Go too big and you’ll be throwing money out the window. Go too small and you could tax your systems, leading to latency and unhappy users. Thankfully, cloud platforms allow you to be cautiously optimistic, with the option to scale your infrastructure up and down easily. This is why it’s so important to choose an API experience solution that delivers greater flexibility than the competition, so that you can scale, adjust and flex your requirements as they evolve.
So where does the Tyk gateway sit in these infrastructure sizing considerations? Read on to find out!
NOTE: Throughout each stage of your growth you should check your infrastructure cost to make sure you are not overspending and/or underutilizing. Do you really need the biggest and best servers for your operation? After all, your ego isn’t going to magically pay your overzealous cloud bill! Check your costs so you know how much you’ll be paying out and factor this into your monthly spend. There’s no reason to be surprised by a giant bill you weren’t expecting!
Determine your baseline
A baseline can be developed differently depending on which scenario you belong to: do you have an existing app with existing traffic or is your app brand new, with no history?
If you have some traffic data, your best bet would be to dig into some metrics revolving around your average latency and your average requests per second (RPS). If you’re unsure of your average latency but know your average RPS, then a simple load testing exercise, covered here, will help you determine the average latency for your current setup.
If you have no traffic, make an educated guess. Doing some research into your application’s flows and expected user base at launch should help with this. This should be done based on your best guess, but be careful not to go too high or too low. You need to find a realistic range that you’re comfortable with.
If your brand new app has no users and is not API call intensive, then provisioning infrastructure that can handle 10,000 RPS with sub-millisecond latency is overkill. While you don’t want to go too small, if you have no traffic then this probably won’t be a concern.
At this stage, you can also look at where these requests are coming from. If you have a global user base, you may look to spin up infrastructure in different regions depending on your use case. You might also look at how you split up your traffic. Will you run multiple smaller servers in dispersed regions or pick a few central hubs and run larger servers?
It’s useful to play with different scenarios, load test each, and determine which is your best starting point. After doing so, check your cost! Can you scale down some of your infrastructure and save a few dollars? Look for savings that won’t affect your customers.
INFRASTRUCTURE BASELINE CHECKLIST
- Gather metrics on current customer base or expected initial users
- Decide whether to split load across multiple smaller servers or fewer larger ones
- Load test to ensure results fit your users’ expectations
- Check your costs and look for savings
Estimate your future needs
Regardless of whether you are a new application or an existing one, you will do some estimating. Some scenarios may make this easier. If your business has an initiative to double your current user base, for example, then you’ll likely be able to whip up some simulations for this and ensure that your system still performs well. With a back-office application, this may be possible, since new users are anticipated.
However, what if you’re using an external system and are unsure of your future needs? Or what if you have a new system with undefined numbers around user growth and adoption? In these scenarios, it’s worth looking at the growth of similar companies to gain a good idea of the market.
Smart optimism will help here. It’s time to create a plan on how you will scale. Based on your system and customer needs, consider what infrastructure you will need to double, triple, quadruple (and so on) your user base. Put together a formal plan which outlines your expected growth, the infrastructure needed to support it, and the cost of said infrastructure. You can use this plan to shop across cloud providers to see which one will be the best fit for your use case, based on features and cost.
Now that you have some numbers and ideas around your infrastructure requirements, execute some load tests based on each stage of your plan. This will help ensure that your infrastructure plan can handle the expected traffic.
FUTURE NEEDS CHECKLIST
- Gather info on potential growth to estimate future load and traffic
- From your baseline instance, form a plan to scale to necessary future limits
- Create a load test to ensure it fits your users’ expectations through each stage of expected growth
- Check your cost and look for savings!
Set up your infrastructure to auto-scale
A tremendous benefit of moving your infrastructure into the cloud is the ability to auto-scale your infrastructure. This helps to take some guesswork out of sizing it, as most public cloud providers allow you to automatically scale based on specific conditions, such as request per second, CPU utilization, timed schedule, or a combination of all three.
Auto-scaling groups are available on most cloud providers. They provide the flexibility to various resources based on a given configured limit or parameter. It’s important to make sure that you still size your instances accordingly and not fully rely on auto-scaling to solve all of your problems because there is a delay in spinning new instances up before they become operational. For example, by default in AWS, your scaling is calculated off metrics within the past five minutes. This means a large spike in load may not be offloaded to the new resources in a timely enough manner to reduce the impact of consumers’ increased requests. Most services also offer, for a charge, a shorter metrics window (AWS is one-minute) which allows for more reactive scaling, although even this comes with its own challenges.
When debating where to set the limits of your auto-scaling groups, it’s useful to use your baseline as your starting point for minimum infrastructure requirements. Then set your upper limits slightly higher than your projected future needs.
Scaling up (horizontally) comes with the challenge of the time delay in bringing up new instances ready for operation. Because scaling isn’t instantaneous, you can’t rely on only that to meet demand. Don’t pick the smallest server possible to run your operation on and then scale up as needed. The better bet would be to find the server configurations that handle your needs the bulk of the time, while also being conscious of cost, then setting up-scaling to handle any peaks of activity. If you are scaling from two instances up to ten instances multiple times throughout the day’s operations, it may be time to go back up to our first point above and reassess your baseline with this new data in-hand.
Another thing that can eat up operating dollars, especially with bigger operations that require larger and more costly infrastructure, is the stabilization and cooldown period that an auto-scaled architecture experiences during scaling events. If your setup begins to spin up a server, it likely will remain active for a set period of time. This is sometimes known as a stabilization period. Google Cloud Platform (GCP), for example, defaults to 10 minutes at the time of writing. So even if the server is brought up and not needed, it will run for 10 minutes on GCP, adding to your monthly charges. The cooldown period, where the server is being ramped down post stabilization period, can last a few minutes. This can also add to monthly costs. Having these events occur across multiple scaling groups, multiple times per day could lead to a costly surprise at the end of the month.
Auto-scaling is an impressive feature when used correctly but be aware of the pitfalls mentioned above. Audit your plan regularly. As you develop higher traffic and loads, move your baseline up and grow your architecture to meet demand.
AUTO-SCALING CHECKLIST
- Take a realistic look at your minimum and maximum auto-scaling needs
- Configure your auto-scaling within your cloud provider
- Test your auto-scaling to make sure it works
- Adjust your auto-scaling plan periodically, based on business needs
- Beware the hidden cost of stabilization and cooldown periods
- Check your costs and look for savings!
Monitor your usage to save cost
The best way to save money on your infrastructure cost and ensure that your planning is working is to look at reports from your cloud provider. By looking at your CPU usage, you can easily see trends, including whether you have overestimated your traffic.
It’s good practice to inspect your usage statistics regularly. Do so frequently with new infrastructure and then space the checkups out as time progresses, or when application users or usage increases by a specific percentage. This all depends on how your operation is set up and what the needs of your organisation are. The key takeaway is that monitoring usage is an effective way to make sure that the dollars you are spending on infrastructure are being utilized well.
You may also want to set up notifications so you are aware of different scaling events that occur. Most cloud providers allow you to set these notifications up. They can be an enormous help for monitoring the status of your auto-scaling infrastructure.
Another benefit of great monitoring and reporting is that when you expand or update your system, and need to go back through infrastructure planning, you will have great metrics to help you establish your baseline and future needs.
MONITORING CHECKLIST
- If needed, set a reminder to audit your utilization reports for the month
- Set up notifications for infrastructure scaling events
- Ask yourself: Should I be bumping up or downgrading my baseline system based on historical usage?
- Change your auto-scale configuration to match trends you see within monitoring reports
- Check your costs and look for savings!
Applying this to your Tyk API Gateway
Now that we’ve looked at sizing your infrastructure, you can apply this knowledge to your Tyk open source API Gateway infrastructure. Below is a chart which outlines some different server offerings within AWS, their relative cost, and the performance we could achieve.
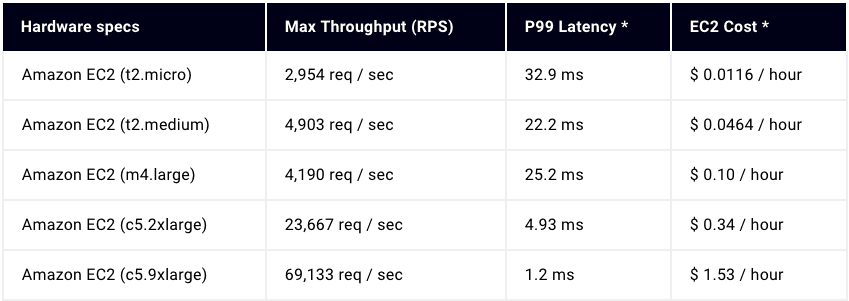
You should now be able to accurately size your infrastructure for Tyk, along with other components of your system, by using some or all of the above-mentioned tactics.
In conclusion, being smart and realistic with your infrastructure sizing requirements is an impressive way to maintain a lean budget or cut down operating costs. Infrastructure is necessary. What isn’t necessary is an enormous architecture that costs your organisation money without delivering any benefit. The right sizing means greater efficiency, which in turn can lead to faster time to value.
The right-sized infrastructure is all you need to succeed and grow your business. To show you how API management — a tool that will help you with that sizing — works, we’ve prepared a short demo video.


