GraphQL Microservices Understanding
GraphQL, the query language created by Facebook, overcomes several of the data retrieval issues common to the more traditional REST APIs, including over-fetching and under-fetching. In over-fetching, an endpoint responds with more data than the client needs, which can add to bandwidth usage. In under-fetching, no endpoint offers sufficient data, so the client must query multiple endpoints to get what it needs.
GraphQL, on the other hand, enables a client to make a single HTTP request to multiple resources and receive the exact data it needs. It offers a simpler, more predictable structure.
This tutorial will demonstrate how to integrate GraphQL with increasingly common microservices, explain the challenges involved and how Tyk’s full lifecycle GraphQL API management platform can address them.
The state of microservices
In a microservice-based architecture, a complex monolithic application is replaced with multiple smaller independent modules, each with a single responsibility. These modules communicate with each other via APIs or event processing and act in harmony to perform the duties of a large application.
Microservices are on the rise now for all types of projects. This 2017 survey by RedHat indicated that 69% of respondents were using microservices for creating new applications and for re-architecting existing ones. The smaller services are being used extensively for building systems internal to an organisation as well as building user-facing software.
Microservices offer several benefits:
- Since each microservice runs independently of the others, it’s easy to add, remove, update, and scale individual microservices without disrupting other services. This results in improved scalability and cost-efficiency for the entire application, since you can focus on only necessary services in case of an increased load.
- When developing microservices, developers can use any programming language and any framework. This means that in a microservice-based application, you are not tied to a specific technology. You can connect microservices written in different languages and different frameworks, choosing the right tool for the job without worrying about compatibility.
- Microservices offer improved fault tolerance. In a monolithic app, when a particular part fails, it can bring the entire app down. In a microservice architecture, if one part fails, the other services can keep working, leaving the app mostly unaffected.
- Small microservices present a small codebase, resulting in easy development, small team size, and fast deployments.
But microservices do have limitations:
- Communication between microservices can be complex. If you have multiple microservices, you might need to write extra code to maintain smooth communication and avoid disruptions.
- A microservice-based architecture can be challenging to set up and maintain. Each service needs its infrastructure and databases to run properly.
- Testing the entire application is a difficult job. Each service needs to be tested independently and verified before the application as a whole can be tested.
In general, though, the benefits outweigh these drawbacks.
Data graphs as the new paradigm
In a microservice-based application, each microservice exposes its own set of APIs, which are “stitched” together to form a cohesive group of APIs for the entire application. Therefore, the data needs to be modelled in a way that eases API development and makes the communication between the services and the external world smooth and efficient. Data graphs are a good solution for enterprise system integrations, enabling multiple applications to work together smoothly, and thus efficient for microservice architecture.
This is how GraphQL allows you to model your data. Your schema has multiple nodes (e.g., `Users`, `Products`, `Subscriptions`) and specifies how they’re interconnected or related (e.g., `Users` can have multiple ordered `Products`, `Products` can be reviewed by `Users`). The API clients can query the data as a graph no matter how it’s stored in the backend, providing flexibility and efficiency.
Implementing GraphQL in microservices
You have microservices that expose GraphQL APIs. How do you combine them to form one complete GraphQL schema?
Using Apollo Federation
Apollo Federation is one of the most well-known methods of implementing GraphQL in microservices. With Apollo Federation, you can divide your data graph across multiple services, called subgraphs. A gateway is then created that combines all the subgraphs. A client can then query the gateway and get access to all the subgraphs.
The following example is a simplified version of the official Apollo Federation GitHub Demo.
First, install the Rover CLI:
npm install -g @apollo/rover
Create a Node.js project and install the required dependencies:
npm install apollo-server @apollo/gateway graphql
Create a GraphQL schema file named `users.graphql` that defines a `User` type and a query to get the current user:
type User @key(fields:"email") {
email:ID!
name: String
totalProductsCreated: Int
}
extend type Query {
me: User
}
Create a file `users_service.js` and save the following code:
const { ApolloServer, gql } = require('apollo-server');
const { buildFederatedSchema } = require('@apollo/federation');
const { readFileSync } = require('fs');
const port = 4000;
const users = [
{
email: '[email protected]',
name: "Apollo Studio Support",
totalProductsCreated: 4
}
]
const typeDefs = gql(readFileSync('./users.graphql', { encoding: 'utf-8' }));
const resolvers = {
User: {
__resolveReference: (reference) => {
return users.find(u => u.email == reference.email);
}
},
Query: {
me: (_, args, context) => {
return users[0];
}
}
}
const server = new ApolloServer({ schema: buildFederatedSchema({ typeDefs, resolvers }) });
server.listen( {port: port} ).then(({ url }) => {
console.log(`???? Users subgraph ready at ${url}`);
}).catch(err => {console.error(err)});
This file works as a microservice responsible for querying the users. We are using dummy data here, but this will probably query some database in a real-life example.
Start the service by running `node users_service.js`. The service starts at `localhost:4000`.
Create `products.graphql`, where you’ll define a `Product` type and related queries:
directive @tag(name: String!) repeatable on FIELD_DEFINITION
type Product @key(fields: "id") @key(fields: "sku package") @key(fields: "sku variation { id }"){
id: ID! @tag(name: "hi from products")
sku: String @tag(name: "hi from products")
package: String
variation: ProductVariation
dimensions: ProductDimension
createdBy: User @provides(fields: "totalProductsCreated")
}
type ProductVariation {
id: ID!
}
type ProductDimension {
size: String
weight: Float
}
extend type Query {
allProducts: [Product]
product(id: ID!): Product
}
extend type User @key(fields: "email") {
email: ID! @external
totalProductsCreated: Int @external
}
Note that the `Product` type references the `User` type. Apollo Federation enables this seamless reference across microservices.
Create `products_service.js` and save the following code:
const { ApolloServer, gql } = require('apollo-server');
const { buildFederatedSchema } = require('@apollo/federation');
const { readFileSync } = require('fs');
const port = 4001;
const products = [
{
id: 'apollo-federation',
sku: 'federation',
package: '@apollo/federation',
variation: "OSS"
},
{
id: 'apollo-studio',
sku: 'studio',
package: '',
variation: "platform"
}
]
const typeDefs = gql(readFileSync('./products.graphql', { encoding: 'utf-8' }));
const resolvers = {
Query: {
allProducts: (_, args, context) => {
return products;
},
product: (_, args, context) => {
return products.find(p => p.id == args.id);
}
},
Product: {
variation: (reference) => {
if (reference.variation) return { id: reference.variation };
return { id: products.find(p => p.id == reference.id).variation }
},
dimensions: () => {
return { size: "1", weight: 1 }
},
createdBy: (reference) => {
return { email: '[email protected]', totalProductsCreated: 1337 }
},
__resolveReference: (reference) => {
if (reference.id)
return products.find(p => p.id == reference.id);
else if (reference.sku && reference.package)
return products.find(p => p.sku == reference.sku && p.package == reference.package);
else
return { id: 'rover', package: '@apollo/rover', ...reference };
}
}
}
const server = new ApolloServer({ schema: buildFederatedSchema({ typeDefs, resolvers }) });
server.listen( {port: port} ).then(({ url }) => {
console.log(`???? Products subgraph ready at ${url}`);
}).catch(err => {console.error(err)});
Start the service by running `node products_service.js`. This service starts at `localhost:4001`.
Finally, create `index.js`, which will house the gateway:
const { ApolloServer } = require('apollo-server');
const { ApolloGateway } = require('@apollo/gateway');
const { readFileSync } = require('fs');
const supergraphSdl = readFileSync("./supergraph.graphql").toString();
const gateway = new ApolloGateway({
supergraphSdl
});
const server = new ApolloServer({
gateway,
});
server.listen(3000).then(({ url }) => {
console.log(`Gateway ready at ${url}`);
}).catch(err => {console.error(err)});
Note that it references `./supergraph.graphql`, which is not present yet. You will use `rover` to combine the subgraphs into a supergraph. But first, `rover` needs to know where the subgraphs are and their corresponding API URL.
Create a file named `supergraph-config.yaml` with the following contents:
subgraphs: products: routing_url: https://localhost:4001 schema: file: ./products.graphql users: routing_url: https://localhost:4000 schema: file: ./users.graphql
This file tells `rover` that the `products` subgraph is in the `products.graphql` file, and the API can be accessed at `https://localhost:4001` and similarly for the `users` subgraph.
The following command creates the supergraph from the two subgraphs:
rover supergraph compose --config ./supergraph-config.yaml > supergraph.graphql
You can check out `supergraph.graphql` to understand how the two subgraphs are connected.
Start the gateway:
node index.js
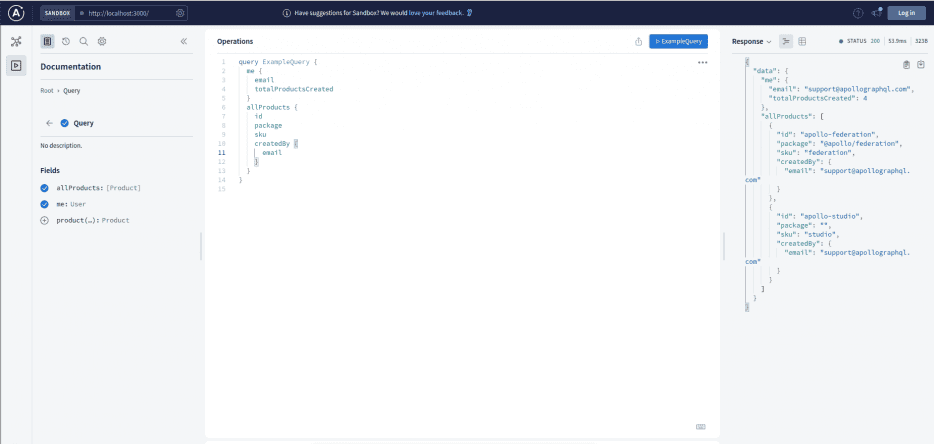
Visit `https://localhost:3000`, where you’ll be redirected to Apollo Studio to try out your GraphQL API.
Here is a sample query:
query ExampleQuery {
me {
email
totalProductsCreated
}
allProducts {
id
package
sku
createdBy {
email
}
}
}
Implications and limitations of GraphQL
Even though GraphQL offers several benefits, you need to keep its limitations in mind.
Security issues
The added complexity of GraphQL raises the risk of security issues. The key issue here is that when dealing with security for GraphQL APIs, you need to consider security at both the HTTP layer (securing the endpoint) as well as the data layer (query depths, node limits and field-based permissions).
Slower query speed
Due to GraphQL’s complex nature, the server will slow down if a client requests too many nested fields from the database. You need to implement mechanisms like max query depth, query complexity weighting, or recursion avoidance to mitigate inefficient client queries.
More difficult caching
With a REST API, it is straightforward to set up a cache at the network level. Since the endpoints are different, you can use a reverse proxy that stores the content of a request and use it as a cache to reduce traffic or keep frequently accessed information ready to use.
In GraphQL, however, there is just one endpoint where all the requests are sent. Since every query is different, it’s challenging to set up this kind of caching. The next best solution is to use persisted queries, but that adds complexity and can require more tools.
Unclear error handling
GraphQL returns `200 OK` for every request. If there are errors, it adds them to the query, but the status is still `200 OK`. This makes it difficult to handle errors and use monitoring tools, since they usually rely on the response’s status code.
Uneven rate limiting
With GraphQL, a user can file multiple queries in a single API call. This means you could have more difficulty in rate limiting the API, which could lead to the requests timing out or clients getting disconnected.
Full lifecycle GraphQL APIM with Tyk
Tyk is a cloud-native full lifecycle API management platform powered by a powerful open source API gateway. Tyk enables users to build a secure, stable, and scalable API-led business by making it easy to connect and manage GraphQL, REST and gRPC APIs.
Tyk supports GraphQL natively, which means you don’t have to use any external service or process for any GraphQL middleware. However, being a full lifecycle API management platform, you can secure your APIs at the HTTP layer as well as the data layer, set up rate limits, monitor and publish GraphQL APIs using Tyk.
Getting started with Tyk
You can get started with Tyk’s API management platform 3 different ways:
- Tyk self-managed: this installation provides the full Tyk Enterprise API Management platform hosted on your own infrastructure. Here is a comprehensive list of hosting and platform options.
- Tyk cloud: this option enables you to quickly setup Tyk Enterprise API Management platform without needing to manage your own infrastructure. Sign up and get started.
- Tyk open source: you can choose this option if you just want to install the open source gateway. Get started here.
API security
Securing your APIs is one of the primary uses of Tyk. Out of the box the Gateway offers a lot of functionality for securing your APIs and the Gateway itself. Our entire suite of security features is available to be used with your GraphQL service. This means that you can have your GraphQL service focus on core functionality needed by the service and leave the management features up to Tyk.
Some of the popular authentication and authorisation methods available out of the box include:
Query depth limiting
The depth of a query is defined by the highest amount of nested selection sets in a query. Malicious GraphQL queries usually leverage queries with a deep depth which can lead to your servers crashing.
One strategy to mitigate this is to restrict the maximum allowable query depth a client is allowed to make. Tyk contains a configurable query depth limit to reduce concerns about the depth of a query which has the potential to crash your server.
Field-based permissions
One of the tougher parts of managing GraphQL is the ability to limit certain fields to certain users. Tyk makes this very simple by enabling you to set which fields are available right in the policy you create for the API or user. Granular configuration is instantly applied to any of the user’s future queries. This helps you to protect sensitive fields or even expose a subset of your Graph dependent on the consumer.
Rate limiting and quotas
Rate limits are calculated in Requests Per Second (RPS). A request quota is similar to a rate limit, as it allows a certain number of requests through in a time period. However traditionally these periods are much longer. Tyk has a built in quota and rate limiting mechanism to ensure that your APIs are secure and so that you can manage and monetise traffic to and from your APIs.
API publishing
The Tyk Developer Portal is a small CMS-like system that enables you to expose a facade of your APIs and then allow third-party developers to register and consume your APIs. Upon publishing your GraphQL API, your API consumers can navigate through a GraphQL Playground, with an IDE complete with Intelli-sense.
Conclusion
GraphQL offers multiple benefits, especially in an omni-channel distribution environment. Its graph-based structure makes it well suited for integration with microservices, and using it with an API management platform enables rapid development and easy management for the success of an API-first business.