Just about every mobile and web application is backed by at least one database. These applications often require a web-based API to expose the database(s) for storing, querying and retrieving necessary application data. But is exposing our data model directly to other developers the best approach to API design?
This article discusses the difference between data model design and API design, and why we often use data models for our APIs. We’ll consider whether this is the data model design approach is right for APIs and cover some techniques for ensuring that your API design hides your internal implementation details to ensure greater API longevity.
What is a data model?
A data model defines how information is stored and retrieved to support a solution. It is an abstract model that reveals exactly what an app can (and cannot) offer to the end user by explicitly defining the data’s elements and how they relate to one another, as well as how they relate to the properties of real-world entities.
Role of a data model in software development
Data models introduce standardisation to the process of defining and formatting the contents of a database. By structuring how data is stored and modelling relationships – often in a visual format – data models can support software development using relational, object and graph databases.
Types of data models
Just as there are three main types of databases (relational, object and graph), there are three main types of data model: relational, dimensional and entity-relationship. Other data model types exist (such as flat, object-role, object-relational, relational, multi-value, network, hierarchical and star schema) but are less commonly used.
- Relational data modelling is the most well-established and most commonly used. It features fixed format records, with rows and columns used to arrange the data.
- Dimensional data modelling is less structured and rigid, with business context often driving the approach.
- Entity relationship data modelling is more abstract and conceptual. This data model example is particularly useful in software engineering.
Data modelling and design process
Designing a data model isn’t a quick process. It begins with diagramming how data will flow into and out of a database. This process forms the foundation of decisions around the data formats, structures and relationships that will enable the data to flow efficiently.
What is data model design useful for? Everything! The framework that your data model provides will enable different systems to use the data, thanks to the standardisation that it shapes and delivers.
Data models are an implementation detail
Data models are a constant with web development. When new team members join, one of the first questions is, “Can I see the data model for the app?”
Your data model is optimized for the internal details of your application – including the decisions you have made about programming language, framework and database vendor. This means that, if you design your API to directly map to your database, you risk exposing these internal implementation details to your API consumers. Hardly ideal.
Also, should your API consumers really get the luxury of seeing the details of your data model and code? They didn’t sit in on the endless meetings that resulted in the multitude of decisions that drove your data model design and they don’t have the context of why your data model was designed in a certain way.
However, many teams have made the decision to expose an implementation decision – their data model – as an external API. Why?
Why do we model our APIs from the data model?
Teams often choose to model their APIs from data models. There are several reasons for this:
- It’s familiar – developers building the API often modelled the data, so a bottom-up approach is usually the most comfortable for them
- It’s faster – directly mapping a data model to an API is the fastest route for the API provider, when time is limited (and when isn’t it?!)
- It’s flexible – we often think that offering finer-grained access via your API allows consumers the greatest flexibility; however, this comes at the expense of slower application performance and more effort at integration time (as we explore below)
Before you make the leap directly from your data model into an API, it’s important to reconsider what problems data models solve:
- Transactional queries from end-users, via web, mobile and API clients
- Optimizing for read-based and/or write-based throughput, through data denormalization, physical storage optimizations and caching strategies
- Reporting and/or ad hoc query support through star schemas, snowflake schemas and other data warehousing strategies
A data model doesn’t concern itself with solving the desired outcomes of your API consumers. Instead, it addresses the architectural and operational needs of the solution. It’s up to you to build APIs and applications on top of the data model to provide the capabilities and desired outcomes that your API consumers need.
Simply mirroring the data model as an API typically isn’t enough to solve the problems that API consumers encounter.
What happens when we expose our data model as an API?
In the effort to deliver APIs that are familiar, fast, and flexible, we push much of the burden of the API onto consumers:
Ever-changing APIs: Database schema changes will result in a constantly changing API, as the API is forced to keep in lockstep with the underlying database. This change to the data model will force consumers to rewrite their API integration code every time the underlying data model changes, resulting in a change to the API definition.
Network chattiness: Exposing link tables as separate API endpoints will cause API “chattiness”, similar to how an n+1 query problem degrades database performance. However, while an n+1 problem can be a performance bottleneck for databases, API chattiness will have a devastating impact on API consumption performance due to the many separate HTTP calls necessary to render a single UI screen.
Confusing API details: Columns optimized for query performance, such as a CHAR(1) column that uses character codes to indicate status, become meaningless to your consumers without additional clarification.
Exposing sensitive data: Tools that build APIs directly from databases often expose all columns with a table using SELECT * FROM [table name]. However, this can expose data that API consumers should never see, such as personally identifiable information (PII). It may also expose data that helps hackers compromise systems through a better understanding of the internal details of the API.
Exposing implementation details: Applications are designed and built on top of many decisions, constraints and other internal details. Directly exposing your database pushes the results of these decisions directly to your API consumers, without the benefit of the reasons why they exist.
Flexibility for the consumer comes at a price. Unless the vast majority of your API consumers want this level of control, it is best to focus on an API design that is separate from your data model, by hiding the implementation details of your app.
Your API design should hide implementation details
The technique of hiding internal implementation details and exposing an external API has been rooted in software design for decades. Terms such as modularization, loose coupling and high cohesion are associated with great software design. Let’s review some of these concepts:
Modules are the smallest atomic unit within a software program and may be composed of one or more source files. Modules have a public-facing API to expose the functionality that they offer. Modules are sometimes known as components.
High cohesion is a term used when the code within a module is all closely related to the same functionality. A highly cohesive module results in less “spaghetti code”, as method calls aren’t jumping all over the codebase. Instead, they are confined to one area, typically a code package or namespace.
Loose coupling hides a module’s internal details away from other modules, restricting the knowledge between modules to a public interface or API that other areas of the code can invoke.
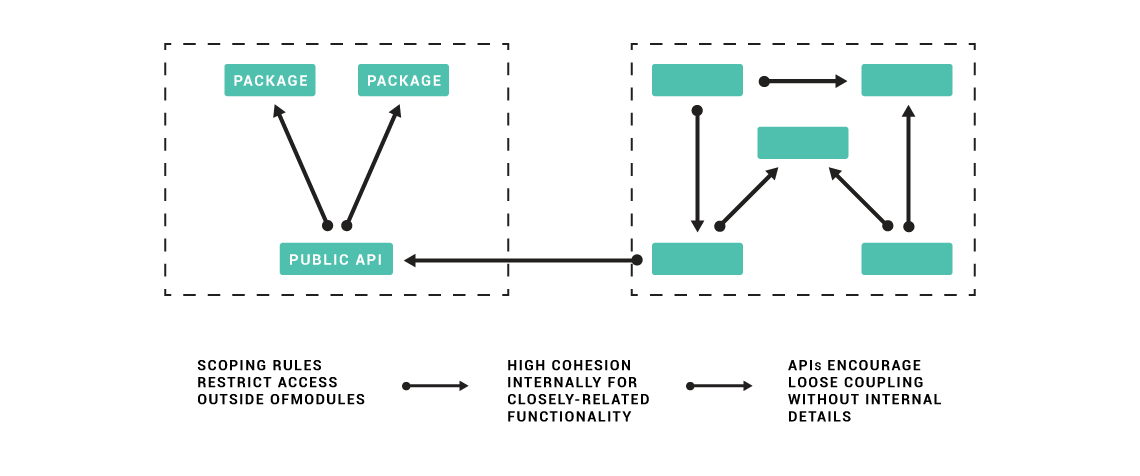
When we apply these concepts into larger software solutions, we hide implementation details within a module from other modules. This results in some basic rules for modular software development that will benefit your API design:
- A module’s internal implementation details should be hidden (e.g. its data model, classes/objects/functions and the events it emits to process internal logic)
- A module’s API is a contract with other modules that should not change when internal implementation details change (e.g. data model changes or switching to a new framework)
- A module may emit messages and/or business events related to its capabilities, but they should not expose the internal implementation details (e.g. moving from RabbitMQ to Kafka to achieve greater scale shouldn’t impact API consumers)
By extending these rules to web-based APIs, we create modular APIs that focus on providing a set of capabilities to API consumers. These capabilities may be driven by a request/response HTTP API call or by subscribing to messages and events from the API through webhooks or websockets. As long as the capabilities that the API offers continues to adhere to the contract defined by the API, your API consumers can continue to use the API without fear of underlying implementation changes that could cause their integration code to stop functioning.
Data model vs. API: what’s the difference?
The fundamental difference between data models and APIs is that a data model relates to how information is stored and retrieved. An API, on the other hand, relates to the way in which consumers experience your app. The data model definition doesn’t bear in mind what your API consumers need. As such, it’s essential to treat your API as a product, not simply an extension of your database data model.
Conclusion: be an API consumer advocate
As mentioned earlier, teams often default to directly exposing their data model as it is familiar, faster and more flexible. Your API consumers care about these same attributes – but from their point of view, not yours. Remember:
- Your API consumers want an API that is familiar to them, not to your implementation team
- Your API consumers want an API that is fast for them to integrate, not for your internal team to implement
- Your API consumers want an API that is flexible by offering capabilities to get things done, without creating lots of HTTP calls and stitching data together to achieve their desired outcomes
Finally, it is important to remember that five hours saved by your team may cost tens to hundreds of hours to your API consumers. This is because every consumer has to deal with the same API design flaws because of your exposed implementation details. A great API design makes it easy for API consumers by hiding internal implementation details, leading to faster integration and happy developers.
Time to find out more? You can speak to the Tyk team about winning API design or book a demo to see Tyk in action.