Ever wanted to build a new GraphQL service with your existing infrastructure and services? Want to solve some of your pressing service integration problems? This is exactly what Tyk’s Universal Data Graph was built to do!
The problem
So you have multiple services and endpoints that your teams or users are using. This is very typical of modern development and can lead to complexity when developing new front-end components or any time when multiple data sources are used. There are a few ways we could work with this scenario or improve to make it easier:
Option 1 – Issue multiple queries in the front-end to retrieve data
- One of the most common methods in modern development
- Lots of requests and coordination required
- Latency and timeouts are a concern
- Services need to be coded if they don’t exist, increasing cost and time to market
Option 2 – Build a new GQL or BFF service
- Relatively complex and requires specific knowledge for coding, modelling, and architecture
- Very complex and costly to produce and move to market
Option 3 – Use Tyk’s Universal Data Graph!
The vision
The premise behind UDG is that within the API gateway itself you can connect multiple data sources and stitch them together into a single schema to create new API products. Whether the data source be a RESTful API, an existing GraphQL service, a database, or even a Kafka stream, you can use Tyk’s Universal Data Graph to wire it all up and create a brand new GraphQL service with all the data exposed through one endpoint. The management and operation of the endpoints built with UDG should be improved and easier than using a traditional Enterprise Service Bus configuration.
Being able to build fully-functional GraphQL endpoints right in Tyk without building any new infrastructure was the key objective in creating the Universal Data Graph functionalities. The process aims to be simple, straight-forward, and to produce production-ready GraphQL endpoints in minutes. With the intuitive dashboard UI, just a few clicks leads to brand new API products with no coding involved and all using existing infrastructure and services. Build a schema, hook up your data, and start issuing queries.
Building a schema
The first step in the journey of creating your first endpoint with UDG is to create a schema for your data. In the schema you can add objects and fields which align with the data you are looking to integrate together. This can be done in the schema editor via text or in a more visual interface as well. This will define the objects and fields that your users will be able to issue queries for once your endpoint goes live. Unfamiliar with GraphQL schemas? They are simply a JSON structure that shows objects, fields, and the data types that those fields consist of.
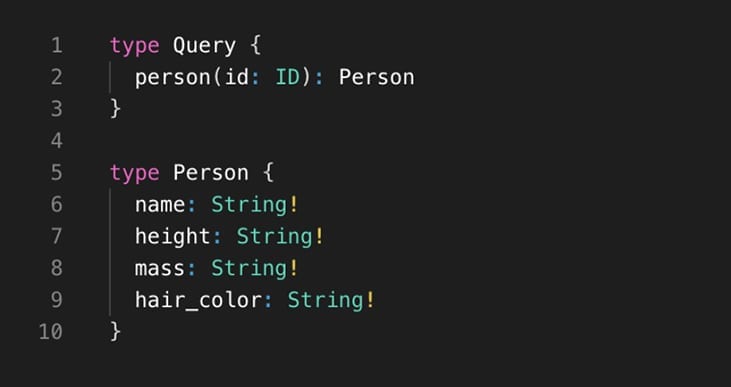
As simple or complex as you want your schema to be, UDG can handle it. Once defined, we then need to start thinking about how we will source this data.
What are data sources?
Once a schema is created then we begin to look at how we want to retrieve the data needed to populate that schema. This is where data sources come into play! What we are essentially doing is saying that a specific field or object in the schema should be populated from this specified source. The great part with UDG is that we are able to build a fairly complex schema and populate all the fields and objects from as many data sources as we would like.
For example, if we had a RESTful endpoint that could retrieve X, Y, and Z fields then while wiring up the data sources to the schema we are able to say that Y field in the schema should be derived from Y field in the specified data source. Here is a high level example of how it works:
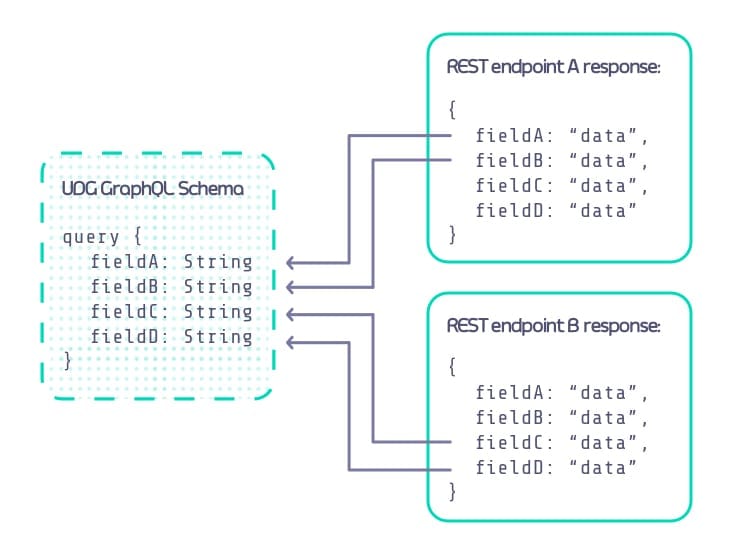
As you can see we have defined a UDG GraphQL schema with 4 fields and have then specified where that data is sourced from, in this case 2 different RESTful endpoints. When using multiple data sources to create a single GraphQL response it is known as “schema stitching”.
With Tyk’s 3.0 release, the first to introduce the UDG capabilities, we have added in a few possible data sources so far. More will be introduced to the platform in future releases but currently we are able to offer the following data sources:
- Tyk GraphQL – Already have a GraphQL endpoint added in Tyk? You’ll be able to add this as a data source in your unified data graph you’ll be creating with Tyk’s Universal Data Graph.
- Tyk REST – Have a RESTful API in Tyk that you want to use as a data source? You can use that as well!
- GraphQL – If you have a GraphQL endpoint you’d like to use that isn’t already connected and protected through Tyk, you can point to its location and also use it as a data source!
- REST – This could be an internal or external API that has not been added into Tyk.Even if the RESTful API does not run through your Tyk gateway you can still use it as a source in just the same fashion as a REST endpoint that is wired up in Tyk.
As we move forward with the Universal Data Graph you can expect to see widespread support for many different data sources including integration with relational and noSQL databases and pub sub/streaming services.
How does it work under the hood?
If you’re a technical person you probably want to know exactly how this all works. The premise of UDG is simple and luckily so are the processes that actually make it come to life!
When stitching together schemas using Tyk’s Universal Data Graph the client sees a single GraphQL response. But what actually happens behind the scenes when we have multiple data sources? Let’s try and elaborate on this in a simple example.
We have 2 services that we will use for this demonstration: a GraphQL service to retrieve basic info on a country and a RESTful service that will return the population for that country.
As mentioned previously, first we would create a schema which would depict exactly what we want our available data to look like. This can be done right in the dashboard in just a few moments.
Once the schema is defined, we need to let Tyk know where the data is going to come from by defining the data sources for each type or field we defined in the data. In our example here we have 3 fields: code, name, and population. Looking at the following diagram we can see that we will be grabbing some of the data from our GraphQL endpoint and some from the REST endpoint.
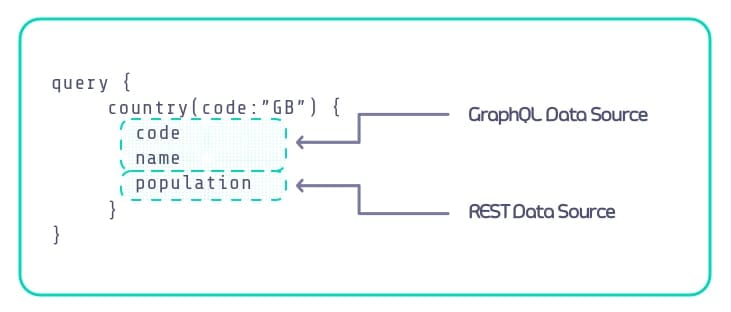
The above query is exactly what users of this new GraphQL endpoint would issue, Tyk takes care of actually getting the data!
After defining where the data is coming from, we can then move on to actually trying out the query. So what happens when we actually issue the query?
#1 – The GraphQL endpoint is queried first using a query that Tyk has built based on the data source and schema info input into Tyk. The data for code and name is then retrieved using a query similar to the following:
query {
country(code: "GB") {
code
name
}
}Data from that call is then returned to Tyk to be merged into the response back to the caller of the original query. The data returned that Tyk will work with will look similar to this:
{
"data" : {
"country": {
"code": "GB",
"name": "United Kingdom"
}
}
}#2 – the REST call is dispatched to retrieve the population field. This call is a GET request issued to:
GET https://restcountries.eu/rest/v2/alpha/GB
Which will then return the following data to also be merged into the response from Tyk:
{
"region": "Europe",
"subregion": "Northern Europe",
"population": 65110000
}#3 – At this point all of our needed data has been resolved and returned. Tyk now builds the response using this data and returns it to the caller in a single GraphQL response like so:
{
"data": {
"country": {
"code": "GB",
"name": "United Kingdom",
"pop": 65110000
}
}So as you can see, no new services need to be built since we are leveraging already existing data sources, all of this can be configured right in Tyk with no code needed, and it can all be ready in a matter of minutes!
UDG in action
If you want to see all of this in action, we have a great video outlining how we stitched together multiple RESTful endpoints into a single unified data graph usings Tyk’s UDG functionality. Take a look below!
How will you use UDG?
Since UDG is so simple to get up and running with your existing services it allows you to very easily experiment. If you’re looking to combine your related services into a single data graph to help developers using this data, UDG is the perfect solution! It also means that you can continue to support the systems currently using the services you’ll be using within your UDG service. No new services, no changes to existing services, and no changes to the systems leveraging what is already in place.
So, use UDG to build new services without all the work. Use it to experiment and play with the power of GraphQL without all the overhead of developing a brand-new ground-up service.This may be just the tool you’ve been looking for and the easiest introduction to using GraphQL yet!
So that leaves us with one final question: what will you build with UDG? Get a free two-week trial and find out.


