APIs commonly require a client to send a request to the server to receive new data; that is, the page requests data from the server. This client-server interaction style is common to REST-based APIs. Tyk makes it easy to manage the full lifecycle of REST-based APIs using a variety of patterns and design decisions, as we cover below in terms of polling and async APIs.
If a client wishes to know when something new is available, it must periodically send a request to the API to check for data modifications. This pattern is known as polling and is a standard solution for clients that need to become aware of new data or be notified of backend events.
What is an async API?
Asynchronous APIs (or async APIs) are an API interaction style that allow the server to inform the consumer when something has changed. Instead of polling APIs, meaning that there is inherent wastefulness in the event notification process with requests being driven by the client, the async API approach means that it is the server that can drive the sending of requests.
Let’s look at some popular technologies that help us to create async APIs , along with how they work and when/when not to use them.
What is API polling?
API polling is where the client sends requests to an endpoint repeatedly. It then compares the requests to see if any of the information has changed. The requests can be at regular intervals or made with randomized delays or exponential backoff.
What is polling an API used for? Well, it can work well if you need very frequent updates but don’t mind that they’re not in real time. It also has its own set of challenges – more on that in a moment. First, let’s look at some common polling patterns.
Common pitfalls: The challenges of API polling
Polling isn’t an ideal solution. It is complex, wasteful and delivers a poor user experience. Let’s examine these challenges before we look at how to overcome them – both through API polling best practices and through an alternative interaction style that pushes data from the server to the client using HTTP.
1. Polling is (often) complex
Polling can be implemented by the client on top of just about any API that uses a request-response style. Since REST APIs fit this model, particularly those that apply the CRUD resource pattern, it is straightforward for a client to add polling support by calling a GET method occasionally to look for new data.
Typical API designs that support polling by default may look like this example:
HTTP/1.1 GET /tasksAccept: application/json[ { "name": "Task 1", … }, … ]
Seems simple, right? Make a request to GET /tasks every 5 seconds to see if anything new has changed. Not really. Several things could go wrong:
- The API sends responses back with default, non-optimal sorting, e.g. oldest-to-newest. We then must request all entries to find out if anything new is available, often requiring us to keep a list of the IDs we already know about.
- Rate limiting prevents us from making the requests often enough to support the solution’s needs
- The data offered by the API doesn’t provide enough details for the client to determine if a specific event has occurred, such as a data updated event
Of course, there are a few ways to mitigate some of these issues, including the use of entity tags (ETags) with conditional requests to check for changes or lightweight endpoints that can check for changes since a given timestamp.
While polling is often a default solution, it is not always the best. Sometimes it requires writing considerable code to work around the limitations of an API that wasn’t designed for polling.
2. It is wasteful
According to a 2013 survey, Zapier says polling is wasteful . Only 1.5% of API requests result in new data. This means that 98.5% of API requests send back data that hasn’t changed!
Zapier mentions how this waste is experienced not just on the app:
Polling is the process of repeatedly hitting the same endpoint looking for new data. We don’t like doing this (it’s wasteful), vendors don’t like us doing it (again, it’s wasteful) and users dislike it (they have to wait a maximum interval to trigger on new data).
Let’s explore an example of an API whose endpoint response payload totals 100KB per request. If one consumer polls the API every 30 seconds, the total data transferred in a 24-hour period is 281MB (2 requests per min * 1440 min * 100KB per request) – per unique consumer.
If we have 100 consumers simultaneously polling, this results in 28GB per day! This calculation doesn’t include the computational and I/O load on our infrastructure, or network transmission costs into/out of cloud infrastructure.
3. It delivers a poor user experience
In the Zapier quote above, it was stated that polling results in a poor user experience because of the lack of real-time notification (“users dislike it”). If you can poll an API, at best, every 30 seconds, the user will only see data changes at this interval. If anything happens during that time, they will be unaware until the next polling interval. Not ideal for web or mobile users who demand near real-time notification.
API polling best practices
If you want to avoid waste and inefficiency, then moving away from polling probably makes sense (and we’ll talk about how you can use async APIs to do that in a moment). However, if you’re determined to stick with a polling API approach, then these API polling best practices should at least ensure you approach the task as efficiently as possible:
- Control polling frequency with HTTP headers – this can reduce unnecessary traffic.
- Don’t poll at fixed intervals – instead, introduce random delays to help avoid API traffic patterns that those with malintent could exploit (it’s a good idea to research which tools are helpful in identifying patterns in polling data, if this is an area of concern).
- Align polling frequency with data changes – thinking strategically about which data changes most frequently means you can better control your approach to polling intervals.
- Use exponential backoff – this can be used as another means of avoiding overloading the API server.
- Encourage efficient use of API responses – educate clients on handling API responses efficiently, like using pagination for large datasets and processing data in batches, where appropriate.
- Use email and messaging service notifications – these can keep clients informed automatically if API requests are delayed.
- Monitor server load – use load testing to keep an eye on the server load and adjust the recommended polling interval accordingly. If your server is under heavy load, advise clients to poll less frequently.
- Provide clear documentation – clearly document the recommended polling practices, including the suggested interval, to guide API consumers in implementing efficient polling mechanisms.
- Implement efficient error handling – timeouts and fallback mechanisms can keep errors contained so that they don’t lead to greater issues.
- Consider client compatibility – web, mobile and desktop clients may have varying bandwidth and performance capabilities, so be sure to factor these in when implementing efficient polling practices.
Common polling patterns
You can effectively handle API polling with a range of approaches designed to optimize polling for real-world applications while overcoming common polling challenges. These polling pattern solutions expand on the best practices above.
Rate limiting and backoff strategies
Polling involves hitting your server with frequent requests. However, you don’t want to overwhelm the server through poor connection management. Rate limiting can help here, as it restricts the number of requests that clients can make within specified timeframes, thus protecting the server and promoting fair usage and reliable performance.
It may be useful to implement adaptive rate limiting as part of your connection management, meaning the client can adjust the frequency of the requests it makes dynamically, based on the responses the server sends. A 429 Too Many Requests response, for example, could trigger the client to queue the request for longer before it next retries.
Also important in polling efficiently is a backoff strategy. One common approach is exponential backoff. This is where the client waits for longer intervals between successive polling attempts after an initial request fails. This ensures that the client doesn’t make any temporary server issues worse by polling repeatedly and relentlessly. Instead, the client backs off for longer periods between each retry, to reduce unnecessary load on the server.
Error handling
Everything from invalid data to network issues can disrupt your smooth polling processes. As such, your polling patterns need to include graceful error handling. This requires thoughtful configuration of your retry logic, so the client knows how to respond when a request fails.
Your retry logic should complement your backoff strategy, to avoid inadvertently creating a denial-of-service issue through frequent repeated requests. It should also include timeout limits, so the client doesn’t tie up its resources waiting indefinitely for responses.
Fallback mechanisms
Sometimes when polling, the client can receive enough errors that something other than simply retrying is required. In such cases, you can configure the client to implement a fallback mechanism for error recovery, such as switching to a different data source. It is also good practice to build in alerting, so that the client can flag up repeated failures, ensuring you can investigate and resolve the issue.
Resource management
Polling consumes resources on both the client side and the server side, so it’s important to optimize resource usage. Doing so helps minimize waste, reduce latency and enhance performance. There are several ways to achieve this:
- Pagination: This reduces request payload sizes through the client requesting smaller chunks of data at a time, rather than entire datasets, saving both processing time and bandwidth usage.
- Partial updates: This is where the API returns only the changes that have occurred since the client last polled it, reducing the load on both client and server.
- Caching: Clients can cache responses for faster response times.
- Network utilization: Shaping your architecture and polling patterns in a way that moves from polling at fixed intervals to pushing updates from the server to the client as soon as they become available can save both bandwidth and resources. Using webhooks and server-sent events (SSE) to achieve this opens up an alternative approach to polling.
Alternatives to API polling
The best practices we discussed above should help ensure your REST API polling is as efficient as possible. However, you’re unlikely to avoid the issues of wastefulness and poor user experience entirely. This is why alternatives such as using webhooks, async API interaction styles and data streaming are so worthy of exploration. Each of these works as a viable alternative to polling a REST API, with the best solution being dependent on your individual use case and priorities. We’ll dive into the details below, but first let’s consider the headline pros and cons of these alternatives to API polling.
| Approach | Description | Benefits | Key considerations | Pros | Cons |
| Polling | The client sends requests to the server to check for updates at fixed intervals | -Easy to implement -Works with all server architectures -No special infrastructure needs | -Can lead to unnecessary server load -High latency in updates -Inefficient for real-time applications | -Simple, widely understood approach -No special setup requirements | -Can be inefficient and wasteful -Data delays between polling intervals |
| Webhooks | The server sends an HTTP request to a client-defined URL when an event occurs, pushing data to the client | -Real-time updates without constant polling -More efficient than polling -Reduces unnecessary server load | -Client has to exposure an endpoint (which can lead to security concerns) -Requires reliable internet connection to receive updates | -Near real-time updates -Low overhead once set up -Efficient for event-drive use cases | -Client must be reachable at all times -Security concerns (e.g. spoofing) -Harder to debug |
| Server-sent events | The server sends real-time updates to the client via a persistent HTTP connection | -Unidirectional communication is simple -Lightweight compared to full WebSockets -Built-in reconnection and event support | -Only works over HTTP(S) -Limited to text-based updates -One way communication (server to client) only | -Easy to set up -Low overhead -Supported natively by browsers -Good for sending frequent updates | -Only one way communication -Limited browser support for older versions -Less flexibility |
| Data streaming | Continuous transmission of data over WebSockets or other persistent connections, for real-time client-server interactions | -Real-time, continuous data flow -Bidirectional (can send and receive data) -Excellent for high frequency updates | -More complex infrastructure -Need for persistent connection means network issues can cause problems | -Low latency for high frequency updates -Bidirectional, so enables two way communication -Good for large, dynamic data sets | -More complex to set up -Can be resource-intensive -Needs a stable, persistent connection |
| Async APIs | APIs where requests and responses are made asynchronously | -Cuts out wastefulness in the event notification process | -Sending of requests is driven by the server | -More efficient, server-driven approach | -Can introduce complexity in managing state and responses |
What if we could push data to the API client?
The ideal situation is to have our servers inform the API client when new data or events are available. However, we can’t do this with a traditional request-response interaction style common with HTTP. We have to find a way to allow servers to push data to the client. Enter async APIs.
What is an async API?
Asynchronous APIs (async APIs) are an API interaction style that allow the server to inform the consumer when something has changed. Instead of polling APIs, where there is inherent wastefulness in the event notification process with requests being driven by the client, the async API approach means the server drives the sending of requests.
You can learn more about what async APIs are in the Tyk Learning Center.
Choosing the right async pattern
With any API-based architecture, choosing the right API design patterns and data integration patterns is crucial to meeting the needs of your use case. Each approach has its own pros and cons in terms of performance, responsiveness and complexity, meaning the needs of your specific event-driven architecture will dictate your approach.
Our recent article on tools and DevOps for async APIs provides some further useful pointers on this topic.
Migration strategies
The decision to migrate to async APIs is obviously not one to be taken lightly. As with any migration, you’ll need to take it step-by-step, at the very least:
- Assessing your current architecture: Will your current architecture support the move to async APIs? Map out clearly what additional services or resources will you need to migrate successfully.
- Planning the migration: Plan everything from expenditure to scheduling to minimize disruption to your day-to-day business. A migration that achieves great things, but disrupts business operations along the way, can end up causing more problems than it solves.
- Managing your async APIs: Ensure you use an API management platform that handles async APIs, enabling you to achieve the same standards of security, performance and observability that you expect for your other APIs.
- Handling legacy clients: Ensure your async APIs can integrate seamlessly with any legacy clients, for a smooth migration that supports future scalability.
- Testing and validation: Test and validate continuously to ensure that everything is working as planned and delivering the results you expected.
Async APIs using server-sent events
Server-sent events, or SSE for short, is based on the EventSource browser interface standardised as part of HTML5 by the W3C. It defines the use of HTTP to support longer-lived connections to allow servers to push data back to the client. These incoming messages are often designed as events that include associated data.
While SSE was originally designed to support pushing data to a web app, it is becoming a more popular way to push data to API clients while avoiding the challenges of polling.
How does SSE work?
SSE uses a standard HTTP connection, but holds onto the connection for a longer period of time rather than disconnecting immediately. This connection allows servers to push data back to the client when it becomes available:
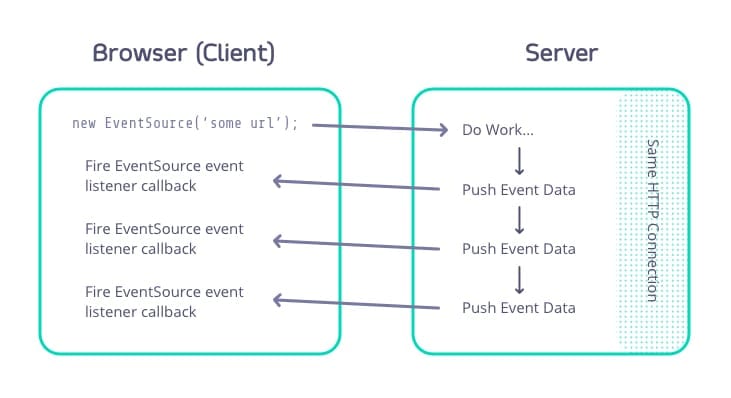
The specification outlines a few options for the format of the data coming back, allowing for event names, comments, single or multi-line text-based data, and event identifiers.
Below is an example of how we might stream back new tasks as they are created:
GET /tasks/event-stream HTTP/1.1
Accept: text/event-stream
Cache-Control: no-cache
...additional request headers...
HTTP/1.1 200 OK
Date: Tue, 18 Dec 2018 08:56:53 GMT
...additional response headers...
: this is a comment, useful for developers debugging an SSE
connection
task_created:
data: {"id": "12345"}
id: 12345
task_created:
data: {"id": "6789"}
id: 6789
- Pretty simple and quite flexible. The format for the data field may be any text-based content, from simple data points to single-line JSON payloads. We are also able to support multiple lines if we wish through the use of multiple >data: prefixed lines.We can even offer a mixture of events from the same connection, rather than requiring a connect-per-event-type.
Notice the identifiers for each event? Clients may use this to recover missed events if you go offline. The specification supports the use of the Last-Event-ID HTTP header, provided by the client when establishing the connection.The server will start the event stream immediately with events following the last event ID, sending events missed while offline. Simple, yet powerful!SSE use cases
- State change notifications to a front-end application, such as a browser or mobile app, to keep a user interface in sync with the latest server-side state.
- Business events over HTTP, without requiring access to an internal message broker such as RabbitMQ or Kafka.
- Streaming long-running queries or complex aggregations as results become available, rather than waiting for all the results to be obtained and pushed to the client at once.
However, SSE does have a few cases where it may not be a fit:
- Your API gateway isn’t capable of handling long-running connections or has a brief timeout period (e.g. less than 30 seconds). While this isn’t a show-stopper, it will require the client to reconnect more often.
- You are targeting browsers that do not support SSE ( compatible browsers ).
- You need bi-directional communication between client and server. Here, you may wish to explore WebSockets, as SSE is server push only.
The W3C specification is easy to read and offers several examples. If you are interested in learning more about how SSE works, consult the specification along with this page from Mozilla if you wish to ensure you are able to target compatible browsers . You may also wish to check out Simon Prickett’s article on Medium, “A Look at Server-Sent Events” , for a deeper look at how SSE works.
Server-to-server async APIs using webhooks
Webhooks are web-based callbacks that allow API servers to notify interested apps when an event has occurred. Unlike traditional callbacks, which occur within the same codebase, webhooks occur over the web, using an HTTP POST. The term webhooks was coined by Jeff Lindsay in 2007.
The power of GitHub webhooks
GitHub has offered webhooks for many years. Anytime a developer pushes a commit to their GitHub-hosted repository, it will issue webhook-based callbacks to any registered subscribers. These callbacks are often used to drive automated build processes as part of a full CI/CD pipeline.
Here is how a typical GitHub webhook notification flow works:
- A developer pushes new code to a GitHub-hosted repository (public or private).
- GitHub publishes the event to its own private “Webhook Relay” service. This service is responsible for notifying any and all registered webhooks for the specific repo.
- The “Webhook Relay” then publishes the event to each registered webhook subscriber using the “Webhook Relay agent”, which acts on behalf of the webhook subscription to ensure that the registered webhook is notified successfully.
- The agent is also responsible for retries and failure notifications if the webhook is unavailable or results in an error.
- The registered webhook receives the event from the “Webhook Relay agent” – in this case, Jenkins. Jenkins receives the event details, then responds with a 200 OK back to the agent. At this point, GitHub’s work is done.
- Separately, Jenkins executes a fresh build process, first by fetching the latest code from the GitHub-hosted repo based on the commit details provided within the webhook callback. GitHub has no idea this is happening – all it knows is that it performed a callback to a specific URL with the details of the event.
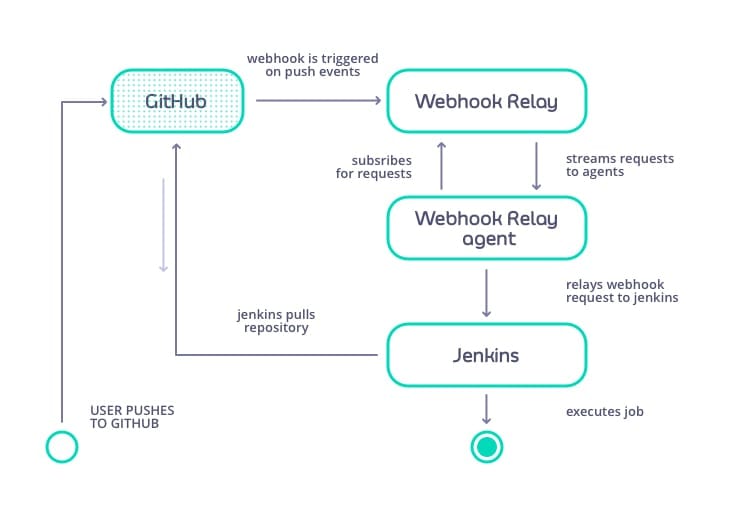
Prior to GitHub’s webhooks, software had to be installed on the server hosting the repository. By externalising these concerns outside of GitHub’s servers, it has opened up a whole new marketplace for hosted, SaaS-based CI/CD tooling from vendors such as CircleCI , Shippable and Travis CI . All with a single webhook – and without any prior involvement or knowledge by GitHub!
How do webhooks work?
The API server makes a POST call to a URL that is provided by the system wishing to receive the callbacks.
For example, an interested subscriber may register to receive new task event notifications to an API endpoint we created, e.g. POST /callbacks/new-tasks. The API server then sends a POST request with the details of the event to this URL.
An important note about webhooks: The subscribing app must provide the endpoint necessary to receive the webhook callback, and it must be accessible to the API. Thus, this style of interaction isn’t appropriate for mobile apps, browser apps or private apps hosted inside a firewall, as they cannot offer a publicly accessible endpoint to receive the POST callback.
However, it will work between private APIs and private apps on the same internal network as long as the appropriate ingress rules are present.
API polling vs webhooks
There was a time when everyone used API polling, sure. But those days are gone. As we’ve shown above, REST API polling is resource-intensive and highly inefficient. That said, polling does still have its use cases, particularly if you need frequent updates that aren’t in real time.
However, if you need real time and/or infrequent updates then you’re likely to land on the webhooks side of the API polling vs webhooks debate. Switching from client-driven polling requests to server-driven webhook requests is a neat and tidy solution.
The fact that webhooks can be automatically triggered each time an event occurs means that there is no longer any need for the wastefulness that is so inherent to the traditional approach to polling APIs.

Choosing between lean and rich event payloads
One of the common questions that emerges for teams designing async APIs is around the size of the event payloads. There are two common options: lean events and rich events (sometimes referred to as “thin” and “fat” events, respectively).
Lean events send the minimal amount of information necessary for the client to know what happened. This may include the type of event and the ID of the resource that the event occurred. For example:
{
"event": {
"eventType": "task.created",
"resourceType": "task",
"resourceId": "abc123"
}
}
Lean events are useful when you want to ensure that the notification event is minimal in size and details. This forces the callback endpoint to fetch the latest details about the resources involved in the event using a request/response style API interaction.
On the other hand, rich events send all of the related information for the event, including any resource representations that may be useful for the callback to process. For example:
{
"event": {
"eventType": "task.created",
"resourceType": "task",
"resourceDetails": {
"id": "abc123",
"name": "My Task",
...
}
}
}
Rich events are useful when the callback processor needs to know everything about the event to take the appropriate action. Perhaps they need to have an exact snapshot of resource state at the time of the event.
In this case, they should not be required to make an API call to fetch the latest details – especially if those details may have changed since the event was published.
In either case, the event may include hypermedia links to inform subscribers where they can go to obtain more information. For example
{
"event": {
"eventType": "task.created",
"resourceType": " task ",
"resourceId": "abc123",
"_links": [
{ "href":"/tasks/abc123", "rel":"self" },
{ "href":"/tasks", "rel":"list" }
]
}
}
Capturing your async API definitions
Capturing the definition of your webhook callbacks in the OpenAPI Specification has been challenging and often met with frustration – until now. Starting with OpenAPI Specification v3, support for callbacks has been added.
This example demonstrates how to define the endpoint for subscribing to webhooks, along with an example definition for the webhook callback itself. You can also read an interview with OAS creator Tony Tam and watch a video on how OAS v3 supports webhooks.
For those that are still using OpenAPI Specification v2, you cannot take advantage of these improvements. API provider teams have three options:
- Upgrade to support OAS v3
- Add callback support through some custom extensions while remaining on OAS v2
- Capture your webhooks using the new AsyncAPI specification
The AsyncAPI specification is a standard that is gaining ground for capturing all channels that offer event notification. From message brokers to SSE and Kafka streams, this standard is becoming popular as a one-stop location to define your message formats and the message-driven protocols available.
It is important to note that this specification isn’t related to OAS, but has been inspired by it and strives to follow a similar format to make it easier for adoption.
Async APIs vs data streaming
Async APIs push messages and events from an API server to an active subscriber over an HTTP connection. Server-sent events and webhooks are two popular options to support API streaming, but there are many other options.
Unlike async APIs, data streaming focuses on raw data and is often delivered through a technology such as Apache Kafka or Apache Pulsar. Data streaming provides continuous, ordered delivery of atomic messages that represent state change in data.
Since Apache Kafka has popularised data streaming, there has been some confusion about whether to use AsyncAPIs or data streaming for messaging and event notification. I recommend the following guidelines as a starting point to determine which option is the right fit:
- When sharing data for governance or when needing to analyze near real-time data as it becomes available, use data streaming.
- When sharing events or data change notifications, use webhooks when subscribers will be other systems capable of exposing an HTTP POST operation to receive the callback.
- When sharing events or data change notifications for external partner consumption, but the subscriber cannot expose an HTTP POST endpoint, use SSE (or a related technology) to offer an async API interaction style.
In short: Webhooks are for system-to-system callbacks via HTTP POST; API streaming with SSE is best for a resource-oriented event model that supports message and event publications alongside the additional behavior offered by REST-based APIs; data streaming is for continuous data analytics or driving data governance for internal consumption.
Expanding your platform with async APIs
Polling is inefficient for both the client (which has to keep checking) and the server (which has more API requests as a result). Async APIs are useful when you need to push events that occur from your backend system to a browser, mobile app or another application using HTTP callbacks.
The next time you design an API, ask yourself this question: “How could API consumers use event notifications to integrate with my API in a more efficient and robust way?”
Ready for more input? While you’re thinking about polling, it’s worth checking out our article on long-running background jobs, which includes an API polling example. It’s part of our API design guidance series, as is our bulk and batch import article – another resource that you should find helpful.

