In the first part of this series, we examined how API portfolios are evolving by going beyond the traditional business capability APIs commonly found with REST with experience APIs that address device and use-case specific needs. This includes the use of REST alongside GraphQL to provide a robust set of APIs for building solutions. We also looked at event-based APIs that support extending our portfolio beyond its original intent.
In part 2, we will examine the different styles of service and data streaming APIs that help us to decompose complex problems into smaller services while also supporting the data analytics alongside more traditional capability-based APIs.
API Style 4: Service APIs
REST was designed around HTTP in the context of the web. It is designed for coarse-grained communication, not fine-grained communication. Therefore, we need to consider how our API platforms will change as more organisations move to microservices.
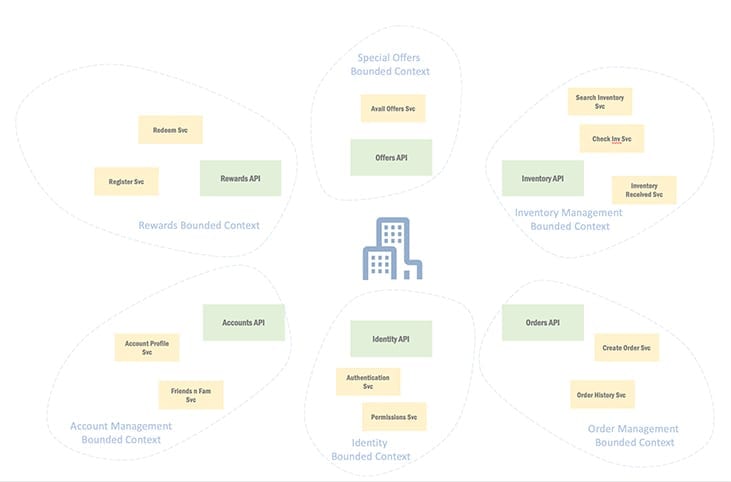
Unlike business capability APIs, microservices take the form of smaller, isolated behaviours. Whereas a business capability API offers a series of operations to realise use cases and solve end-user problems, service APIs deliver only a subset of the operations offered. Services are grouped inside of a bounded context, with a business capability API supplying an external interface for consumption, while hiding the internal service details.
Below is an example diagram that demonstrates how business capability APIs work in concert with microservices:
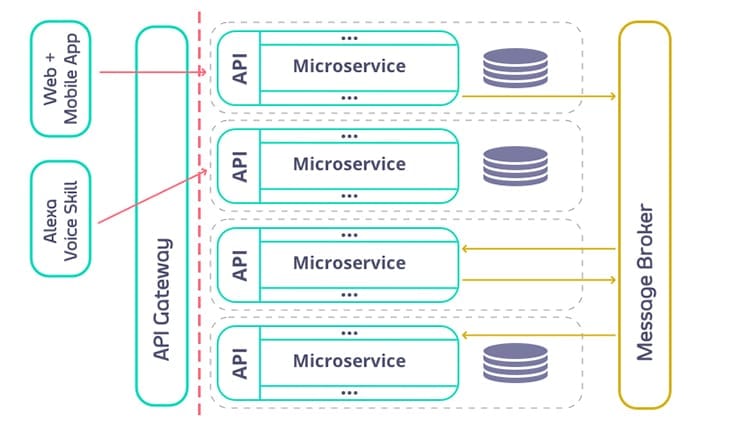
There are some advantages to this style of approach:
- Teams are afford the option of building a bounded, modular monolith to implement the business capability APIs at the start
- Over time, teams may decompose their modular monolith into microservices, without disrupting the operations supplied by the business capability APIs
- Microservices may evolve without breaking business capability APIs, typically through splitting or recombining services based on learning within the bounded context
For smaller organisations, the distinction between business capability APIs and service APIs may be challenging to differentiate. In this case, one option may be to avoid microservices altogether if the burden of building two sets of similar APIs doesn’t offer the business value and development velocity desired.
Alternatively, complex solutions that merit a microservice approach may start by routing all service traffic through an API gateway. This approach enables the API gateway to aggregate and organise the service APIs together into a series of cohesive business capability APIs.
Some organisations are moving toward microservices. Those early in the journey begin by building request-response services, much like the REST-like APIs they might build for business capability APIs we discussed in part 1 of this series. Over time, organisations realise that asynchronous microservices also benefit from a message-oriented approach as well as the synchronous request/response style of HTTP. These message-driven services respond to incoming command messages or react to events from other services.
To support both synchronous and asynchronous styles of microservices, organisations are looking beyond the typical HTTP-based API styles, such as REST. Since the REST style is common due to an abundance of development frameworks, they are often combined with message brokers, Kafka brokers, and/or Websockets to support both HTTP-based and event-based service APIs. Like event-based APIs, message-based services benefit from capturing their definition using the AsyncAPI specification.
Some organisations have even started to use API protocols such as gRPC to optimise microservice calls, since gRPC supports both synchronous and asynchronous styles of communication using the optimised and bi-directional HTTP/2 protocol. gRPC uses an interface definition language (IDL) to define the service procedures available and the inputs and outputs:
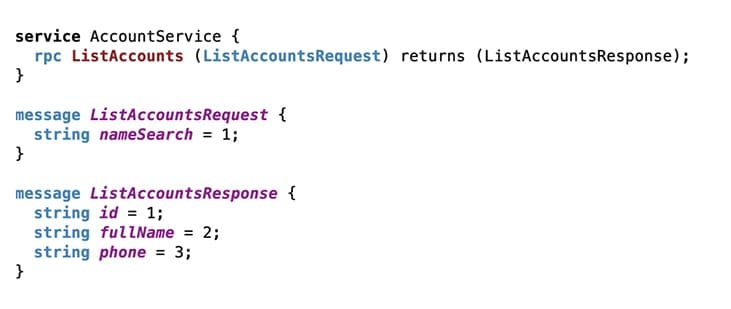
Note that since gRPC is based in the remote procedure call (RPC) style of distributed computing, the inputs and outputs are type and order specific, unlike HTTP-based APIs that use messages rather than over-the-network procedure calls. These messages typically take the form of JSON or XML, though HTTP content negotiation offers more flexibility beyond these popular media types.
For organisations undertaking a microservice journey, I recommend the use of the microservice design canvas, shown below, to map the high-level requirements of the service into a service API:
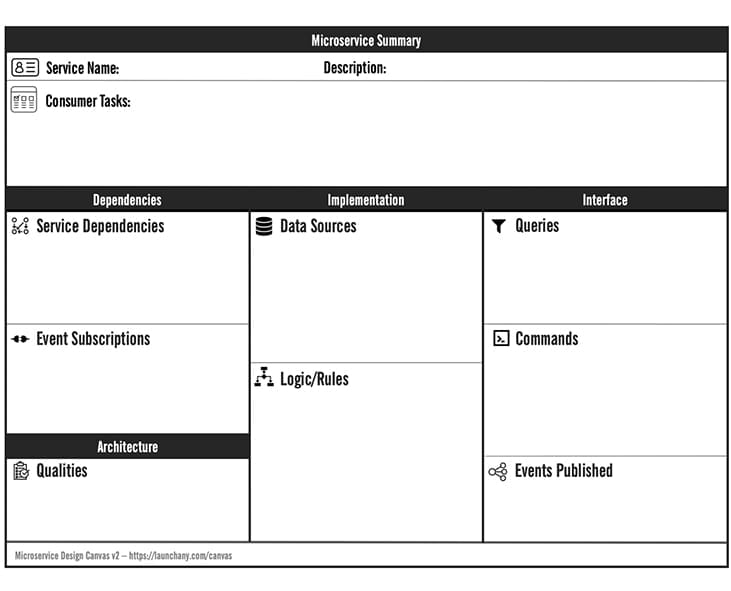
The canvas captures concerns such as the queries and commands the microservice will offer, as well as any published events. Additionally, it helps to identify the events the service may subscribe to events published by other services. When our service definition is viewed in this way, we begin to see what API styles and protocols may be the best fit for the microservice and, therefore, for our API platform.
As mentioned earlier, API gateways may be used with microservices to externalise these services as a larger set of APIs consumable by internal developers, partners, or customers. This is called “north-south” traffic as requests go from applications to APIs. Microservices introduce the addition of “east-west” traffic, where services may communicate with other services directly, without the need for an externally-facing API gateway.
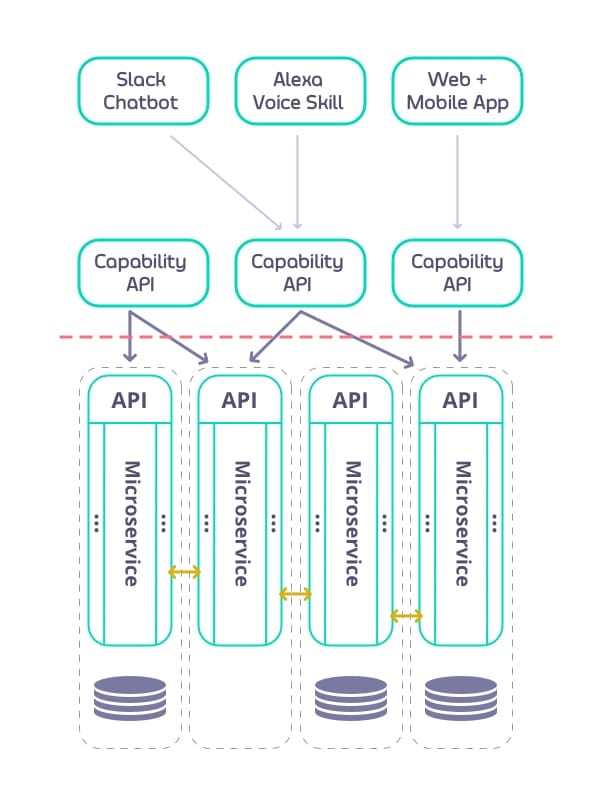
Some organisations opt to use API gateways between their services, while others are opting to use a service mesh for service-to-service communication. Most organisations start with an API gateway to protect their north-south traffic, then evaluate whether additional API gateways or the use of a service mesh is best suited for east-west traffic.
API Style 5: Stream and data-oriented APIs
Until recently, data management was limited to DBA-equipped teams that established processes and standards for organising and optimising data queries. However, organisations are seeing high volume and/or high velocity data management pushing the bounds of traditional data management. Data streaming has become a new practice for many organisations to support the querying of large datasets that exceed the normal bounds of business capability APIs built on REST and GraphQL.
High velocity and high volume data is ingested into data lakes from all over the organisation and from external sources, typically using tools such as Apache Kafka, Apache Pulsar, or Amazon Kinesis. Tools such as Apache Spark are used to query and stream data into various analytics systems, transforming the data for their own needs. The results are then acted upon, perhaps storing the results back into the data lake or into a transactional system or data warehouse. Business capability APIs use the stored results to power end-user behaviour or offer reporting dashboards. This process is shown in the diagram below:
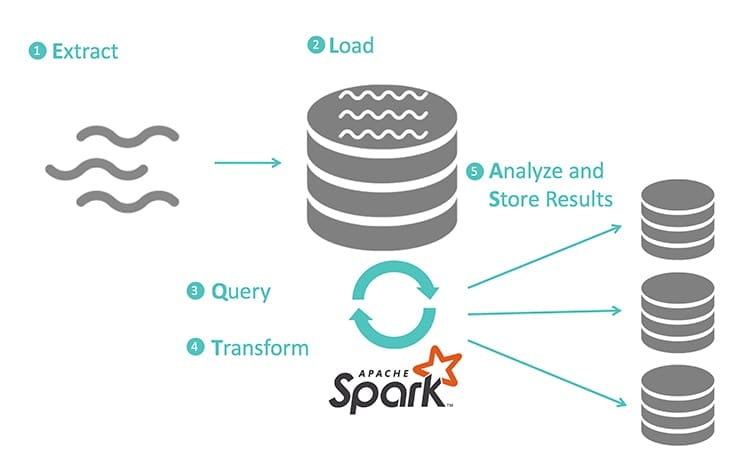
As the diagram shows, organisations are being forced to move beyond the traditional extract, transform, and load (ETL) processes to a new series of processes. Instead, an extract, load, query, transform, and analyse (ELQTA) approach to data management is now required. This new ELQTA process pushes the centralised management of data structures and ETL scripts to the edge of the organisation. These processes require a lifecycle around data structure definitions, ensuring that these data structures, commonly housed in data lakes, are discoverable and consumable. This is leading to the rise of data-oriented APIs.
Data-oriented APIs are not like the traditional REST or RPC-based APIs most of us are familiar with today. Rather, they are APIs that consist of a query or streaming protocol (e.g. Apache Spark or Apache Kafka) alongside the data structure definitions. These data definitions represent the various structured and semi-structured data found in the data lake. Formats such as Apache Avro are becoming common for capturing this format as it forms the basis for most Apache Kafka solutions.
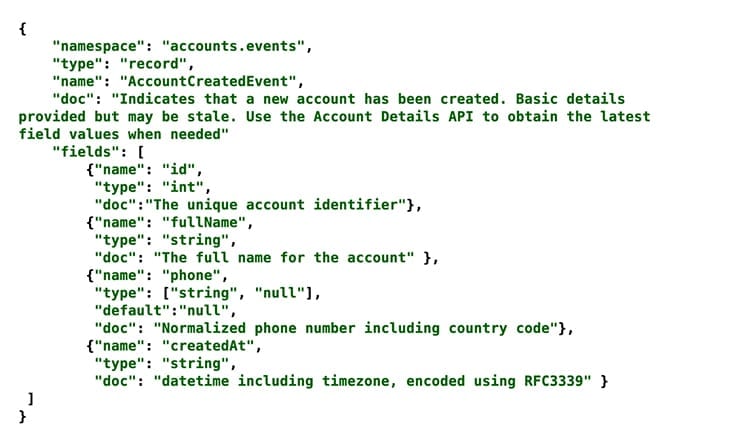
What is becoming apparent is that these data structures and streaming solutions are yet another style of API that is becoming part of the API program. API designers must understand where data is sourced from to determine the volume of data that will need to be offered. They must also consider the veracity of the data as well as the velocity of change as part of their API design. For regulated industries, such as banking, data lineage is also a concern. Designing a business capability API without understanding the underlying data may lead to poor interface design. At worst, it could lead to bugs or even the leaking of sensitive PII data. API design will be forever intertwined with data management for most organisations.
Since many of the protocols used to offer data-oriented APIs live outside of HTTP, traditional API gateways may not be involved. However, selecting the appropriate API gateway is important for the HTTP-based APIs built on top of the results of data analytics.
Part 2 Conclusion
In part 2, we examined the different styles of service and data streaming APIs that help us to decompose complex problems into smaller APIs. We also looked at how data management is becoming part of the API landscape, specifically around data analytics supported by data lakes and streaming. In part 3, we will look at how serverless and infrastructure/network APIs are moving the concerns of API design and management into the operations space.

