A popular myth is that REST-based APIs must be CRUD-based – that couldn’t be further from the truth. It is simply one pattern in our API design toolbox.
This article outlines a variety of additional patterns available for REST-based APIs. The intent isn’t to be fully exhaustive, but to open the options for API designers uncertain about how to apply designs beyond CRUD to REST-based APIs.
A quick review of CRUD
CRUD-based APIs refer to APIs that offer resource collections that contain instances, mimicking the (c)reate, (r)ead, (u)pdate, and (d)elete lifecycle pattern. This pattern is useful when we have a collection of resource instances that represent content or state. It often follows this familiar pattern:
- GET /articles – List/paginate/filter the list of available articles
- POST /articles – Create a new article
- GET /articles/{articleId} – Retrieve the representation of an article instance
- PATCH /articles/{articleId}– Update specific fields for an article instance
- DELETE /articles/{articleId} – Delete a specific article instance
REST: Moving Beyond CRUD
Before we explore alternative patterns, we need to address a serious misconception about REST:
There is nothing about CRUD being a requirement for a “RESTful” API.
In fact, I did a search in Fielding’s dissertation, just to be certain, and found 0 results:

When speaking about REST-based APIs, many conflate the idea of resources that utilize a CRUD-based pattern with REST itself. However, the idea of an HTTP resource is very abstract and not directly related to our database design:
“This specification does not limit the scope of what might be a
resource; rather, the term “resource” is used in a general sense
for whatever might be identified by a URI.” – RFC 3986
In fact, they can represent anything digital or physical:
“Familiar examples include an electronic document, an image, a source of information with a consistent purpose (e.g., “today’s weather report for Los Angeles”), a service (e.g., an HTTP-to-SMS gateway), and a collection of other resources. A resource is not necessarily accessible via the Internet; e.g., human beings, corporations, and bound books in a library can also be resources. Likewise, abstract concepts can be resources, such as the operators and operands of a mathematical equation, the types of a relationship (e.g., “parent” or “employee”), or numeric values (e.g., zero, one, and infinity).” – RFC 3986
REST is about constraining the way we interact between client and server, to take advantage of what the protocol (in this case, HTTP) offers. These constraints give us freedom to focus on our API design:
- Uniform interface – requests from different clients look the same, whether the client is a browser, mobile device, or anything else
- Client-server separation – the client and the server act independently and the interaction between them is only in the form of requests and responses
- Stateless – the server does not remember anything about the user who uses the API, so all necessary information to process the request must be provided by the client on each request. Note: this isn’t about storing server-side state
- Layered system – the client is agnostic as to how many layers, if any, there are between the client and the actual server responding to the request. This is a key principle of HTTP, allowing for caching servers, reverse proxies, and access security layering – all transparent to the client sending the request
- Cacheable – the server response must contain information about whether or not the data is cacheable, allowing the client and/or intermediaries (see layered constraint, above) to cache data outside of the API server
- Code-on-demand (optional) – the client can request code from the server, usually in the form of a script, for client-side execution
Again, there is nothing about REST requiring a resource with a CRUD-based lifecycle. CRUD is a pattern we can apply to our APIs, but it isn’t a requirement for composing a REST-based API.
This gives us a little more freedom when we design our APIs, as we can offer resources with a CRUD-based lifecycle when it is appropriate, while mixing in functional resources when CRUD isn’t necessary.
We don’t have to be limited to this pattern when designing APIs. Let’s explore some other options that can help us design a great API that meet the needs of current and future developers.
Extending CRUD with additional lifecycle endpoints
A common situation in API design is the need to go beyond the typical CRUD interaction model. For example, some APIs may need to support actions such as submit, approve, and decline. With our somewhat limited action verbs in HTTP, how can we add this to our API?
One option that is taken is to use a status field that is modified via a PATCH request. While this is one option, I like to take a slightly different approach by offering functional endpoints for my resource instances. For example, I might extend the design, above, with the following:
- POST /articles/{articleId}/submit
- POST /articles/{articleId}/approve
- POST /articles/{articleId}/decline
- POST /articles/{articleId}/publish
In this design, we have functional endpoints for our article instances within the collection, available via a POST action. Why might we take this approach? A few reasons:
- Our APIs can have better fine-grained access management at the API management layer, since each specific action is a unique URL that can be assigned different role-based access. We therefore decouple our access rights from the code into the deployment model, giving us flexibility to further restrict endpoint access without requiring code changes to enforce these restrictions
- The workflow our API supports is more explicit, as we don’t have to look at the PATCHendpoint to understand the valid status values we can update, along with the state machine rules of what is allowed to be transitioned-to and when. Each endpoint declares this independently and more expressively
- Finally, we are able to utilize hypermedia links more effectively in our response payloads by offering unique URLs for the additional lifecycle endpoints. For example, the author might see the following API response:
{ “name”:”My new article”, “status”:”draft”, … “_links”: [ {“rel”:“submit”, “href”:”/articles/12345/submit”} ] }
While an editor might see the following, once the draft is submitted:
{ “name”:”My new article”, “status”:”submitted”, … “_links”: [ {“rel”:“approve”, “href”:”/articles/12345/approve”}, {“rel”:“decline”, “href”:”/articles/12345/decline”} ] }
Our clients are able to understand what action(s) are currently available to the client based on the user’s permissions (e.g. an editor might be able to approve, decline, and publish while an author may only be able to submit an article in draft mode) through the presence or absence of links to each of our lifecycle endpoints
This is quite a powerful option for API designs that needs to go beyond the standard create, read, update, and delete actions for some or all of the resources it offers.
Functional resources for search and calculations
What if the capability we need to offer our consumers doesn’t require a collection of resources? What if we just need to compute a value and return it? Does that break our REST-based approach? It doesn’t have to, as long as we abide by the rules of HTTP and select the right action verb for the need, typically POST or GET.
Some common examples might include:
- GET /search?q=api
- GET /postal-code-to-region?postalCode=78701
- POST /calc-sales-tax
The common naming pattern I’ve seen for functional resources is in the form of verb-noun or sometimes just verb. This makes it easy for the developer to understand it is a functional resource, rather than a resource collection that often follows the pluralized noun format (e.g. projects, accounts, customers).
Notice that the examples, above, require that you pass in all of the necessary information at once. Functional resources are an acceptable API design option, unless you begin to realize that the resource has a lifecycle (e.g. create, read) or has to capture state from the client. In this case, it is better to use stateful resources via the CRUD pattern to make it easier to interact with the resource collection and instances.
Transactional Resources for complex, long-running workflows
During the days of SOAP and web services, WS-Transaction was a specification designed to wrap multiple web service calls into a single, distributed transaction. This introduced considerable complexity to service design.
With a REST-based approach, we may still encounter complexities with our API design that require us to span transactions across multiple HTTP requests. Fear not – we have a solution that is much easier and flexible.
Resources may be designed not just to represent business objects, but also long-running transactions or complex workflows. These resource collections represent the long-running transaction or workflow that we need to offer API consumers. Let’s look at an example that manages a reservation process for a hotel:
- We first submit a request to create a new reservations resource instance with our desired room details, e.g. POST/reservations
- We then use this resource instance to capture or modify details about the reservation over time including start and end date, number of people in our party, additional requests, upsells, etc. This endpoint might be PATCH/reservations/abc1234, which we will use as often as required until our reservation reflects the customer’s desired needs
- For added flexibility and auditing purposes, each time we make a modification we may capture the change as a separate nested resource. This will allow us to pull a history of changes to our reservation, e.g. GET/reservations/abc1234/modifications
- If necessary, we can establish an expiration date for our reservation – perhaps 7 days after creation. If we try to make an update or pay for the reservation after the expiration, we would receive a 400 Bad Request or perhaps a 409 Conflict
- When ready, the customer can submit a payment to our reservation instance, e.g. POST/reservations/abc1234/payments
- The result of a successful payment results in a booking, e.g. GET/bookings/ghurefh345
- Subsequent changes to the booking would be handled directly, e.g. PATCH/bookings/ghurefh345, but may trigger specific side-effects such as the need for additional payment or a partial or complete refund. This is because we are in a different context than the initial reservation process, one of a paying customer rather than someone shopping for a reservation
This is a powerful way to model a long-running transaction or workflow process, keep an audit trail of changes to the resource, and support an expiration period for transactions. All while staying within the constraints of a REST-based API design and avoiding added complexity on the API consumer.
Singleton resources: there can be only one
Singleton resources are useful when you do not require a collection of resources for your API. Singleton resources may represent a virtual resource for direct interaction of an existing resource instance, e.g. GET /me in place of GET /users/12345.
APIs may also offer nested singleton resources, when there is a one and only one relationship between the parent resource and its child resource, e.g. PUT /accounts/5678/preferences.
Singleton resources may already exist without the need to create them, or they may require creation via a POST endpoint. While singleton resources may not offer the full spectrum of lifecycles like their collection-based brethren, they should still adhere to the proper selection of HTTP action verbs that best match the lifecycle necessary.
Bulk and batch resource operations
Some resources require importing lots of data at once to prevent submitting 100s to 1000s of individual POST operations (a slow and tedious process). This is sometimes called ‘bulk’ or ‘batch’-based processing. While these terms are sometimes used interchangeably, I differentiate them in the following way:
Bulk operations process each submitted record independently, allowing failures to be caught but the remainder of the import to succeed. This means that out of 2000 records, perhaps 76 of them failed while the remaining 1924 records were imported successfully.
Bulk operations, such as POST /accounts/bulk, should return a 200 OK response code, along with a payload that indicates records that failed to import successfully. The response payload may also include successful records with their generated identifier, should the client wish to track success history for reporting or associate internal data with the identifier known by the remote API.
For bulk imports that will take longer than a few seconds, the API should return validate the request, queue the work to be done, then respond immediately a 202 Accepted response along a Link header to the resource that represents the bulk import process details. Clients may then follow-up to see if the import was completed and obtain the results of the bulk import process, if so desired.
Batch operations process all submitted records within a single pass-or-fail transaction. This means that if 76 records fail in a batch of 2000, none of the records were actually stored. The client will need to correct (or remove) the 76 failed records and resubmit the revised batch.
Batch operations, such as POST /accounts/batch, should return a 200 OK if all records in the batch were stored successfully. In all other cases, the 400 Bad Request may be returned along with a response payload that contains each of the records, the import status of each record, and any additional error details associated with each failed record.
For batch imports that will take longer than a few seconds, the API should return validate the request, queue the work to be done, then respond immediately a 202 Accepted response along a Link header to the resource that represents the batch import process details. Clients may then follow-up to see if the import was completed and obtain the results of the batch import process, if so desired.
Zoom-Embed Pattern: field-level selection and fetching nested resources
Using the zoom-embed pattern, the API supports more customization of the response payload to optimize the client-server interaction. This may be necessary in low-bandwidth networks or devices with limited-CPU capabilities. Clients are able to list the specific fields of a resource that they wish to have returned by the server while skipping those fields they do not need, e.g. GET /accounts/12345?fields=id,name,description.
For resources that contain nested resources, clients are also able to specify additional nested resources to be returned within the response via a query parameter, e.g. GET /accounts/12345?include=preferences.
This pattern prevents clients from making multiple roundtrips, where the client fetches a resource and is then forced to submit a separate HTTP request for each nested resource (sometimes referred to as the “n+1 request anti-pattern”).
This pattern was used successfully for the LinkedIn API, long before GraphQL, as shown below:
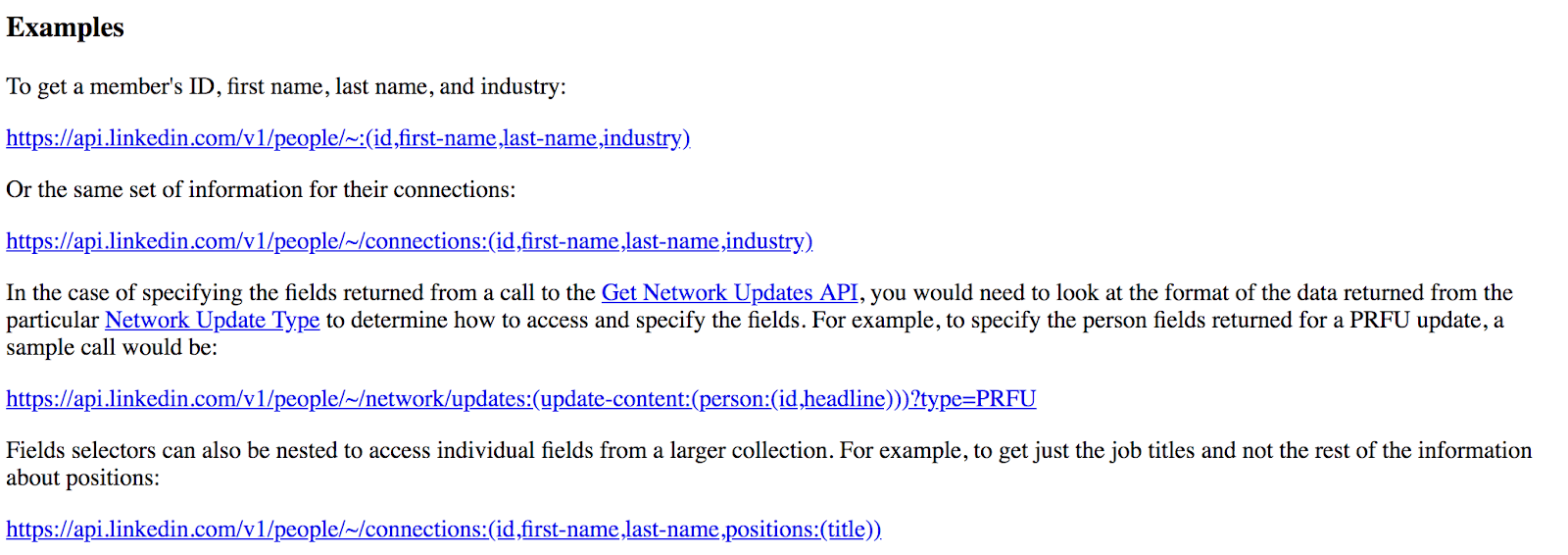
By applying this pattern, we are able to have the best of both worlds: resource collections and instances that follow the pattern we want, plus more control for API consumers to select the amount of data returned without making multiple HTTP requests.
Wrap-up
When speaking about REST-based APIs, many conflate the idea of resources that utilize a CRUD-based pattern with REST itself. However, REST is a set of constraints that help our API mimic the best aspects of the web.
For your next API design, I hope that you take the time to revisit these patterns and see if there are opportunities to incorporate one or more of them into your design to help make your API more evolvable.
Watch our video on converting REST to GraphQL the easy way with Tyk.
Looking for an easy way to manage and maximise your REST APIs? We recently launched Tyk 2.7, the latest version of Tyk Open Source API Gateway and Management Platform. Find out more about 2.7’s 160% performance boost, custom key hashing algorithms and Dashboard user groups over on the Tyk Engineering Blog. The (API) force is strong with this one.