Introduction
The chosen architecture for deploying API Management can significantly impact how easy (or otherwise) APIs are to manage and scale as requirements evolve. In this guide, we will look at different architectural deployment patterns for API Management and assess the merits of each, along with any potential drawbacks.
Requirements around performance, resilience, availability, latency, multi-region deployment and a range of other factors all contribute to decisions over which pattern is the most suitable for a given business. Below, we show how Tyk caters to each of these requirements through a self-managed option that provides outstanding control, a cloud pattern that delivers a high degree of convenience and a hybrid pattern that works as an excellent middle ground.
If your business is in need of effective API management that is attuned to your organisational needs, working through the details below, will put you in a strong position to identify which API deployment pattern not only suits your use-case for today, but can also adapt for tomorrow.
API gateway pattern
API gateways are typically deployed as the single entry point to your underlying services for clients that might need to access those services.
API gateway benefits
From a consumer’s perspective, API gateways are a facade, hiding the complexity of the underlying services / microservices / serverless functions and providing a single point of entry to those services.
By providing a single set of credentials for a suite of APIs, it can considerably reduce the complexity of maintaining multiple API clients and securely storing and managing those credentials.
By employing a facade pattern, API gateways provide a backend-for-frontend to ensure an optimal experience for different API clients. E.g. smaller response payloads for IoT and mobile devices vs more detailed responses for desktop devices.
Gateways typically have the ability to mediate between different API types to provide a uniform frontend irrespective of the underlying protocols used. These might include mediating between synchronous and asynchronous services, such as a GraphQL or REST interface to a Kafka topic.

From the API producer’s perspective, the humble API gateway has become more and more critical to relieve microservices of implementing cross-cutting concerns. It allows API developers to focus on business logic, as opposed to replicating capabilities including security, logging, monitoring, tracing and caching into each individual service.
In addition to the above capabilities, gateways can actively fire events and dynamically disconnect certain routes, paths and services through the use of uptime tests, circuit breakers, timeouts, throttling and retries.
Challenges which will almost certainly be faced by not implementing an API Gateway might include:
- necessity to maintain and update libraries across multiple services
- performance overhead from having a dependency on so much code
- inconsistent logging and monitoring implemented across microservices over time,
- an overall maintenance burden.
Tyk API gateway
In this minimal deployment topology, only the Tyk gateway and Redis are required. Redis is needed to store credentials along with session metadata, track rate-limits and act as a temporary store for request analytics.

Much like putting NginX, Envoy, Traefik in front of your services, Tyk gateway is very similar, although Tyk is more specialised for fronting APIs.
Tyk gateway acts as the policy enforcement point which goes between your API consumers and your upstream services. It ensures that only authenticated and authorised client requests may pass to those services, and enforces rate-limits and quotas. It can check that the upstream services are available, disconnect them when there are problems, and act as a load-balancer to multiple upstream services, validate JWT tokens and perform mediation to mention a few.
The Tyk gateway runtime configurations are either pre-defined by files, environment variables or can be configured via JSON HTTP API in this minimal setup.
As an enterprise (licensed) customer, this is the same gateway your team will be using in production. This means that your developers can spin up a minimal and lightweight Tyk gateway as part of their local developer workflow, confident that their development environment will work in exactly the same way as production.
As an Open Source customer, you can be confident that there is no feature lock-out, the same gateway as used by enterprise clients is the same gateway that you too will be using.
I also touched on the fact that the gateway sends temporary analytics to Redis. These analytics are consumed by a component called Tyk Pump. Similar in functionality to FluentD, Tyk Pump is responsible for ingesting the analytics in Redis, and distributing them to one or more data sinks. These might include Mongo, Kafka, StatsD, CSV, DataDog, ElasticSearch, Splunk and Logz.io to mention a few. Tyk gateway also exposes a Prometheus metrics endpoint for its own health, performance and load.
API management
Deploying gateways manually is great for simple, or highly automated use-cases, where an architect has the capability and time to design and deploy and run things precisely the way that they need. You are pretty much left to your own devices to apply your own governance, workflows and patterns. API management solutions can and should help you to level up and take things considerably further. API Management provides a framework and tooling required to help you scale, with support for different stakeholder workflows – not just the engineers and architects, but also business and product folk.

Tyk Dashboard was developed as a control plane to help you manage your APIs. It exposes a HTTP API and a UI. It introduces various concepts including API design, security policies, API versioning, API cataloguing, APIs as products, role based access control (RBAC), analytics querying and reporting, to mention a few. In the context of deployment patterns though, I would like to speak about three in particular which, when combined, open up a whole matrix of possibilities.
High performance and high availability
In this deployment pattern, you would deploy replica instances of your gateway behind a load balancer. When the gateways boot up, they connect into the Tyk Dashboard control-plane to dynamically pull in their configurations.

In terms of the simplest form of high availability, we can ensure that there are at least 2 gateways. If you need to upgrade a gateway, the load balancer can stop sending traffic to the gateway which is being serviced until the newly upgraded version comes back online, then the process happens again for the remaining gateway(s).
Typically, we find that performance will not be limited by the Tyk gateways, but by the capabilities of the load balancer, your network and the underlying services. That said, under heavy load – say both gateways are at ~80% CPU utilisation – shifting all the traffic from one of the gateways to the only remaining gateway will obviously cause problems for that remaining gateway. If your gateways are under load, you will probably need to think about introducing more gateway instances.
Tyk gateways are extremely lightweight, introduce sub millisecond latency and can handle in the region of 50k rps with just 8 cores. Tyk gateway instances can horizontally scale according to your requirements. If you have over 10 gateway instances, each running hot at 80% CPU, and one instance is taken out of the load balancer, it’s probably OK as the remaining 9 can handle that little bit more traffic. So typically, the more instances you have, the easier it is to distribute the load across them and the more resilient your setup will be.
Inside Kubernetes, gateways can be installed as a deployment with a set number of replicas, or using a horizontal pod autoscaler to automatically scale up and down depending on load. Gateways can also be upgraded using the rolling update strategy, where we can also control the minimum number of gateways that should be available at any given time.
Gateway sharding
Sharding allows different gateway instances to selectively load different sets of APIs. Let’s assume, for simplicity’s sake, that we have two zones in our network – DMZ, and an internal zone. We deploy a gateway cluster to the DMZ and another cluster to the internal zone and apply tags to the gateways appropriately. Now it is possible to make an API publicly or internally available by tagging the API Definition with DMZ or internal.
In a more complex real-life use-case, one of our banking clients needs to serve APIs to 4 differing service-level tiers. Outage of Tier-1 services will require the CEO to make an appearance on the news as it will cause customer debit cards to fail. Tier-2 is for high-priority / availability / heavy duty services, Tier-3 for commodity – still important but recoverable and lower risk. Finally Tier-4 for stuff that doesn’t really matter. As I’m sure you can imagine, it would be desirable for Tier-1 services to be served by their own dedicated gateways alongside much stricter governance. Conversely, Tier-2 and Tier-3 could possibly share gateways and because we don’t want to stifle innovation – we need to increase speed of delivery and not be a blocker to the business – let’s ship Tier-4 services with a much looser governance. This can all be achieved with gateway sharding.
Multi-tenancy
Let’s assume that you have three teams each working with Tyk. It is possible to bootstrap three different organisations into Tyk, meaning that each team will have their own logical space with their own developer portal and without sharing any data between them. Team members can belong to one or more teams, meaning that when they log-in, they may choose which workspace they want to enter.
Additionally, it is possible to manage multiple environments such as staging & production using this multi-tenancy capability. This way, in combination with gateway sharding, you can ensure that staging is as close to production as possible, while ensuring logical isolation of configuration data. In combination with gateway tagging and sharding, it is then possible to neatly promote APIs from staging to production.
Cluster and region distributed API management patterns
In all the previous examples and use-cases, we haven’t yet mentioned anything about cluster or region distributed workloads, from here on, we will refer to both as distributed API management for brevity. The reasons for distributed API management are vast. Use cases for distributed API management range from technical, to legal, to organisational and business needs. This section touches on a handful of common challenges and use-cases.
Servicing API consumers at the edge
API consumers aren’t always living on servers with high throughput connections, often, they are consuming your services via a flaky 3G mobile connection. Whilst your underlying API services might be hosted in North America, strategically placing API gateways closer to your consumers in Europe, Asia or Africa will significantly improve their latency and overall experience of the services you provide. It is often useful or necessary to perform API caching at the edge for further performance enhancements.
Migrating to the cloud, or cloud hopping
There are plenty of reasons why your company might want to migrate from one public cloud platform to another. Whether it be consolidation due to Mergers & Acquisitions, to better alignment of services, improved SLAs and pricing, there are hundreds of different scenarios. Regardless of the reason, over time, it is likely that at some point, your organisation will need to safely move some workloads serving API traffic from one cloud provider to another.
Handling network partitions
You should never trust the network. What happens when things break? How quickly are you able to recover from a disaster?
Compliance, certifications and legal requirements
Health Insurance Portability and Accountability Act (HIPAA) APIs are used to interact with services which control access to healthcare systems and typically handle Protected Healthcare Information (PHI).
The General Data Protection Regulation (GDPR) broadly gives individuals more power over their data with enhanced rights to access, rectify, and erase it, and the ability to freely request the transfer of their information to other platforms.
With a complex organisation, only a small subset of APIs will likely fall under one of these categories. In addition, if PHI, or Personally Identifiable Information (PII) is redacted from an API response, it will not fall under the rules of HIPAA for example.
In order to achieve compliance, it is often simpler to isolate the services and teams which hold and transfer protected information, meaning that the blast radius requiring compliance remains small.
Finally, it is often necessary to keep data within a jurisdiction. This means that it can be useful for a control plane and data plane to be in different geographical locations, particularly if the organisation operates across multiple jurisdictions.
API teams
This is possibly the most complex use-case. Each organisation has a different management size and structure, and has a different hierarchy. From flat, through to tall, centralised to federated, or somewhere inbetween. These are then often split across products, teams and departments, and often, each works in a slightly different way. This makes best practices for API management extremely difficult to recommend as there is never going to be a one-size fits all solution. By its very nature, a successful API programme is dynamic, it lives and evolves as the organisation grows. This means that what’s the right pattern for an organisation today probably won’t be suitable or scale well for the needs of tomorrow.
As an API program matures, we might go from purely technical team members through to having business stakeholders. These business stakeholders might include Product Managers, API Designers, Technical Writers, and even DevRel to help train, run hackathons and promote use of the APIs. How would the API management platform appropriately serve the needs of all these stakeholders?
Often, each API will be owned by a team. A team might own one or more APIs. How to appropriately manage and retain visibility and governance of those APIs across a complex, continually evolving ecosystem of multiple teams and API styles?

Tyk multi-region
In this deployment pattern, we introduce a new component called Multi-Data-Centre-Bridge, or MDCB for short. MDCB is a microservice application which is deployed alongside Tyk’s dashboard inside a centralised control-plane. Clusters of gateways connect to MDCB via RPC. These gateway clusters can be geographically, or logically remote.

Loading API Definitions
As per all previous architectural patterns, it is possible to leverage tagging and sharding strategies, along with multi tenancy. This means that from a central dashboard, it now becomes possible to manage APIs irrespective of and across multiple geographies, cloud providers and deployment architectures.
When you configure an API inside Tyk Dashboard, you have full control whether this runtime configuration goes to the gateway cluster deployed to Kubernetes in AWS US East, or to the bare metal dedicated Gateways you have deployed inside your Data Centre in Singapore, or the local test gateway cluster you have deployed to your local machine.
Configuration is propagated from the control plane to these remote gateway clusters via RPC. This configuration is then cached in a local Redis cluster. Analytics are also sent via this same RPC channel back to the central control plane.
Propagating API Keys
API keys are typically issued via some catalogue after a portal developer has created an app and requested a subscription to an API Product. This catalogue typically lives alongside the management control plane right next to the multi data centre bridge. Let’s assume we are not doing anything fancy, and it is Tyk that is issuing API keys, rather than something like a dedicated OAuth2/OpenID Connect solution. Our challenge now is that these API Keys and associated permissions and quotas are centrally managed, but the Gateway clusters are globally distributed.
The first time a protected API call arrives at a Tyk Gateway, Tyk checks its internal cache, then the shared cluster cache provided by Redis, and finally queries MDCB via RPC in order to validate the API key. MDCB then returns the key, along with permissions to the Tyk Gateway, which then stores the key within its internal cache and cluster cache within Redis.
When keys or permissions are updated or deleted in that centralised control-plane, events will trigger those remote Gateways to flush their local and cluster caches for that key. Whilst the very first request might introduce a little latency whilst the API key is propagated to the local gateways, subsequent requests arriving at the gateway can be serviced extremely quickly with a local lookup, and other Gateways in the cluster only have to go as far as the local Redis to validate the key. Mechanisms for pre-warming gateway cluster caches with API keys go beyond the scope of this article.
Consistency, availability and partition tolerance
Tyk’s remote Gateway Clusters offer high availability and partition tolerance. That is, Gateway nodes will remain online even if they cannot communicate over RPC with MDCB. Even if they do not have the most recent API key data, they will still continue processing requests. Once connectivity is restored, any keyspace events which were missed will attempt to reconcile based upon a log of events which will buffer inside MDCB.
Tyk Gateways can achieve this because they have multiple cache layers, internal and cluster level through Redis. Key events all happen centrally at the control plane, meaning that it is not possible to perform writes or deletes of keys at the local gateways. Gateways are capable of buffering request analytics during that network partition until recovery and eventually drop the analytics after some time to ensure that traffic can keep flowing.
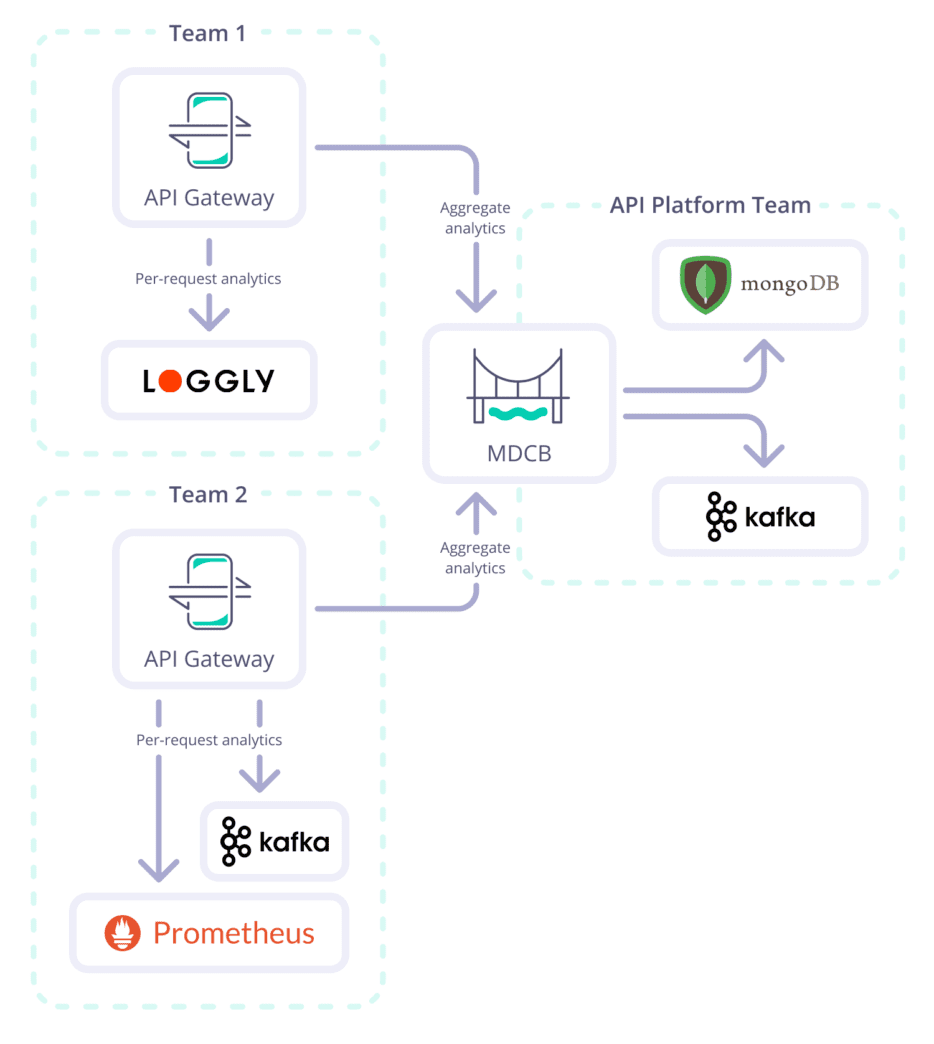
API analytics for teams
We have touched on analytics previously in this article, but all were in the context of analytics being centralised. That’s great if your entire org is using a single analytics solution, but often, the reality is very different. Team 1 will likely be shipping their analytics to Prometheus, and Team 2 will be using Loggly, whilst Team 3 is heavily utilising Kafka. The API Platform team doesn’t require detailed per-request analytics, only aggregate data to see how the platform is being used. So why should the platform team enforce its will when it can cause friction or act as a blocker to potentially many decentralised teams who have different tooling for their use cases?
Tyk Gateway clusters can be deployed each with their own sets of analytics pumps. This enables each team to take ownership of not only their gateway clusters ensuring no noisy neighbours, but also ship analytics to their data sink of choice. Pumps can then also send the required aggregate analytics back to the central platform team as required.
Tyk Cloud
Fully managed API management
Tyk Cloud ultimately provides API management as a managed service. It means that you can operate API management, without having to worry about deployment or maintenance of the underlying infrastructure. What makes Tyk Cloud uniquely powerful, is that it offers the ability to architect that infrastructure according to your needs via a point and click or as Code (IaC) mechanism. Tyk Cloud is also a single tenant SaaS solution, meaning quality of service will not suffer due to noisy neighbours and you can be more confident of increased security in comparison to alternative SaaS solutions.
Tyk Cloud takes care of management of environments and teams, allowing you to deploy your management plane to a continent of your choice. Once your management plane has been deployed, you can then deploy one or more gateway clusters to that home region, or remote regions as per your requirements.
Tyk Cloud takes care of auto scaling each of Tyk’s components as necessary to ensure both high reliability and availability.
Opting for a fully managed SaaS solution can significantly reduce time to market. Cloud instances of the Tyk API management platform can be spun up and upgraded almost instantly in a secure production ready manner, saving the hassle of needing special onboarding and expertise of the Tyk stack. It also removes the requirement to procure hardware or cloud compute, setup, configuration and maintenance.
When considering a fully managed solution it is worth ensuring that network latency is not going to be an issue for your use case. Since the gateways are provided as a cloud service, there will likely be more latency introduced between gateway and your services, than if you were to self host the gateways in your own infrastructure. This makes SaaS gateways potentially better suited to services you wish to expose for external consumption, rather than for internal microservice communication.
Already, an API gateway is adding a network hop. A client request might originate in Europe, hit an API gateway in the USA, and be proxied to a service residing in Singapore. With this in mind, it’s also worth considering if you need to deploy your SaaS gateways closer to your consumers, but targeting a DNS which is capable of cleverly routing to the nearest gateways to mitigate any latency issues.
Hybrid API management
It may not be desired for regulatory, performance or security reasons for certain API traffic to leave an API provider’s infrastructure. Hybrid API management attempts to address many, if not all of the shortcomings mentioned with SaaS with very few of the tradeoffs. A halfway house between the convenience of fully managed and the control, security and performance that you would get from self-managing. This makes hybrid API management particularly suited to the internal API management and microservice communication use-cases..
In this topology, Tyk hosts the management and control plane, much like the fully managed solution, but with the key difference being that the customer self-hosts the Gateways. Hybrid gateways are exactly the same as the multi-region gateways, only rather than pointing to the customer’s MDCB to pull their configurations, they point to Tyk Cloud instead.
Conclusion
Managing APIs goes far beyond picking something that solves a specific problem, deploying it and then letting it run. An API management solution needs to not only support the needs of today, but also be flexible enough architecturally to support the anticipated challenges of tomorrow.
The decisions you make around the architecture for your API management can set your business up for both short-term and longer-term success. The deployment patterns presented provide prompts and sample use-cases to think about your own requirements and which pattern will work best for your business.
With so many variables at play – from technological through to people, culture and teams – it’s important to take a step back and define what it is that you need your APIs to achieve. That knowledge can then help to drive your decision-making around deployment patterns.
If you’re still seeking answers after reading the above, then the Tyk team is here to help. You can speak to us about our self-managed, cloud and hybrid API management options to work out the best way forward for your unique business environment.

