Our clients over at Move.com have written this terrific blog on how they used Tyk Operator to streamline their API management with federated autonomy. Take it away, friends!
I am going to tell you a story. Yes, this is a technical blog post, but the origin story is often the most important thing to know when deciding whether or not to use technology. What drove the team to use a given piece of tech? What problem does it solve? Don’t worry; plenty of technical details will come so you can lean back and get comfortable.
Let the story begin.
The year was 2021, and the pandemic was in full swing. Many of us hadn’t left our homes in months…we might still have been washing our groceries down with Windex. Against this backdrop, we started a major project at Realtor.com to overhaul our API layer and transform how our backend and frontend teams interact.
Lacking a shared infrastructure
You see, we had gone all in on microservices and were paying the price. If microservices are the proverbial hammer, not every part of your tech stack is a nail. Some pieces of your platform can and should be provided as shared components across teams. Most importantly, for our purposes in this article, it is essential to provide shared edge and API layer infrastructure.
We were utterly lacking this shared infrastructure, and each backend team was solving the problem of providing APIs to client teams differently. Teams shared some backend-for-frontend solutions but needed more consistency across groups.
This led to a proliferation of solutions for API management, including several duplicate implementations for rate limiting, token validation, and IP block/allow lists.
Additionally, there were many ways of routing traffic to the backends including API Gateways, CloudFront distributions, and ALBs.
Complex issues holding us back
With an increased surface area of APIs to manage, our teams struggled with various issues:
- The need to deploy changes in multiple places.
- Duplicated work as each entry point needed its own set of edge layer tools.
- More surface area to defend against attack.
This sprawl of API endpoints was painful for our client teams to interact with – causing a lot of additional business logic to be added to our client code base in the form of sawtooth if statements.
We knew all this complexity was holding us back, but where to start? We had several problems to address. Consolidating the syntax and semantics of our APIs behind GraphQL is a related but separate story for another time. For now, we will focus on the issue of network infrastructure sprawl and the lack of consistent, supported paths for edge layer functionality like bot detection, rate-limiting, header injection, and caching.
Searching for a transparent API solution
So, we got to work. A cross-functional team was assembled to investigate options, and immediately, as you can expect with any platforming initiative, we began to hear from members of the organisation who were concerned about the loss of autonomy:
- “Will we have to depend on another team to help us launch our APIs?”
- “Do we have to wait for a platform dev to change our rate limiting?”
- “Won’t this all just slow us down?”
These are great and well-justified questions; how could we remove complexity through centralisation without sacrificing velocity? Clearly, this platform needed to be as transparent and self-service as possible to avoid being seen as an impediment or hurdle.
Enter Tyk
To start building this experience, we looked at products on the market – and this is where we met the lovable green creature that will become the main character of this story. You know her…the Tykling!

What in the world…?!? I uttered under my breath as I stared at a bare-bottomed alien creature. My colleague, Brian, had sent me a link to the Tyk API management platform website, and I was greeted by their cherubic mascot with an equally cherubic bare butt.

My surprise gave way to genuine interest as I read more about Tyk.GraphQL embedded in the gateway? Sweet! Rate limiting, caching, and API sharding? Very Nice! Oh, what is this? Anative Kubernetes operator allowing you to configure your gateway in simple yaml files? Bingo!
This was a turning point for the team when we discovered Tyk Operator and realised what it could do. It is a turning point for this article, as it marks the point where we get more technical.
Tyk Operator
Tyk Operator is a Kubernetes operator, which, to simplify things a bit, is a process that watches for events related to custom resources in a Kubernetes cluster and then takes action when those events occur.
Tyk Operator makes the appropriate API calls to the Tyk dashboard to create, delete, or modify Tyk API definitions and security policies. In this case, the custom resources are aptly named APIDefinition and SecurityPolicy.
This allows teams to configure the gateway and take advantage of Tyk’s impressive collection of middleware by simply defining an API definition and deploying it to Kubernetes. With a few lines of yaml, teams could set up a proxy from our gateway hosts to their service. If they added a few more, they could get JWT token validation. Add a few more, and they had trace header injection.
Best of all, this was done through an existing API standard and deployment model in Kubernetes. No need to add anything new! Teams were happy because they kept their autonomy and agency, and we were delighted as a backend team because we could reduce the complexity and maintenance burden surrounding our systems.
Putting it all together
Let’s look at a high-level diagram detailing the flow of a request, and then we can dive into an example of what one of these API definition resources looks like.
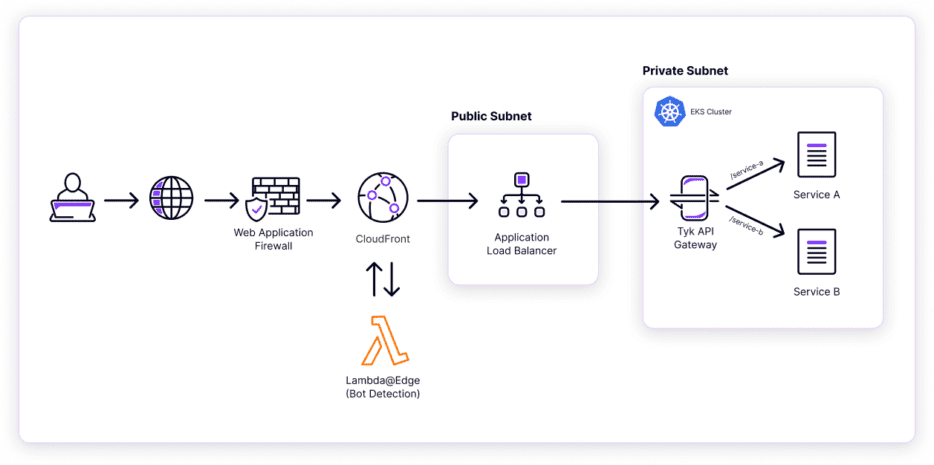
When a client requests one of our APIs, it is first routed to a CloudFront point of presence closest to them. This is where we apply our AWS WAF and its associated firewall rules and integrate them with our bot detection service. Additionally, our CloudFront is configured to cache requests based on backend response headers, allowing us to provide a highly performant cache layer to our clients.
Once the request makes it through CloudFront, it is forwarded on to an application load balancer that fronts our Tyk Gateway deployment. Tyk applies any configured middleware and then, based on the domain and path of the request, forwards the request to its designated upstream service.
Tyk Operator and API definitions
Ok, great! So we see how the requests are routed to the services through Tyk Gateway, but how does the gateway know where to route any individual request? This is where Tyk Operator and the API definitions come into play. Take a look at the following diagram:
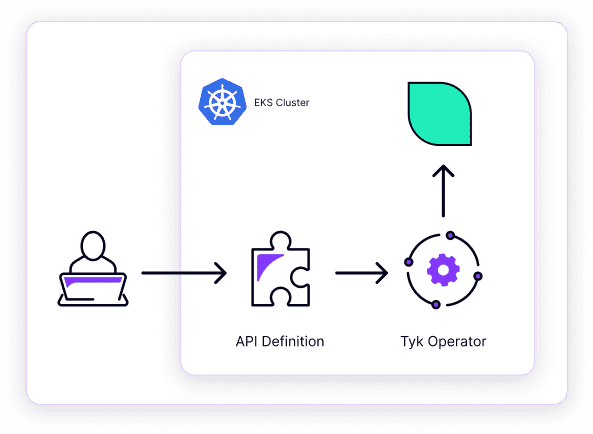
A developer defines a Tyk API definition and then deploys it to the cluster. The Tyk Operator, which is subscribed to cluster events involving API definitions, sees that a new APIDefinition has been added to the cluster. The Operator parses the API definition spec and makes corresponding changes to the gateway via dashboard API calls. The gateway will then hot reload with the new API route available almost instantaneously.
At this point, an astute reader might ask how you prevent two different teams from using the same path to route a request. After all, if teams have the autonomy to deploy these resources, what is to keep multiple teams from claiming the same route?
That is a great question, and I won’t answer it…for now, anyway. It is the subject of another post in this series, so you’ll have to return to learn more 😀.
API definition – an example
Anyhow, I promised I’d show you an example of an API definition, so let’s get to it:
apiVersion: tyk.tyk.io/v1alpha1 kind: ApiDefinition metadata: name: user-delete spec: active: true name: user-delete protocol: http domain: https://my-domain.com proxy: listen_path: /api/v1/users/delete strip_listen_path: true target_url: https://my-upstream-service.com/users/delete jwt_policy_field_name: pol # The id for the policy to apply for all requests to this endpoint jwt_default_policies: ["my-policy"] # jwt_source contains the base64 encoded url for the jwks endpoint. jwt_source: >- "my-jwks-endpoint-b64-encoded" jwt_signing_method: rsa # jwt claim containing the consumer id jwt_identity_base_field: sub active: true auth: auth_header_name: Authorization enable_jwt: true
In the above definition, you can see that we are deploying a route for /api/v1/users/delete.
Requests on this path will be proxied to the target_url. As part of this request, we enable jwt validation for the token in the authorisation header. We can configure token validation by providing a jwks endpoint or signing key in jwt_source and some additional configuration about the embedded claims.
Now, any request to this endpoint on this path must contain a valid, non-expired token in the authorisation header, and all we had to do was add some minimal configuration.
That’s it! Using simple definitions like this, teams can request and receive an API route following the best security, reliability, and performance practices. No need to spin up CloudFront or additional load balancers. No need to write custom middle-tier components. Just write a small yaml file, and you are all set.
As you can tell, we are excited about Tyk, and there is a lot more we’d like to share. Stay tuned to this series for the following articles:
Part 2: Improving developer experience with Tyk and helm library charts
Part 3: Enforcing an API policy with Tyk and Kyverno
Part 4: Splitting traffic across multiple gateways with Tyk API sharding


