Introduction
Service Discovery is a very useful feature for when you have a dynamically changing upstream service set. For example, you have ten Docker containers that are running the same service, and you are load balancing between them, if one or more fail, a new service will spawn but probably on a different IP address. Now the Gateway would need to either be manually reconfigured, or, more appropriately, detect the failure and reconfigure itself. This is what the service discovery module does. We recommend using the SD module in conjunction with the circuit breaker features, as this makes detection and discovery of failures at the gateway level much more dynamic and responsive.Service Discovery: Dashboard
The Service Discovery settings are located in the Core tab from the API Designer.
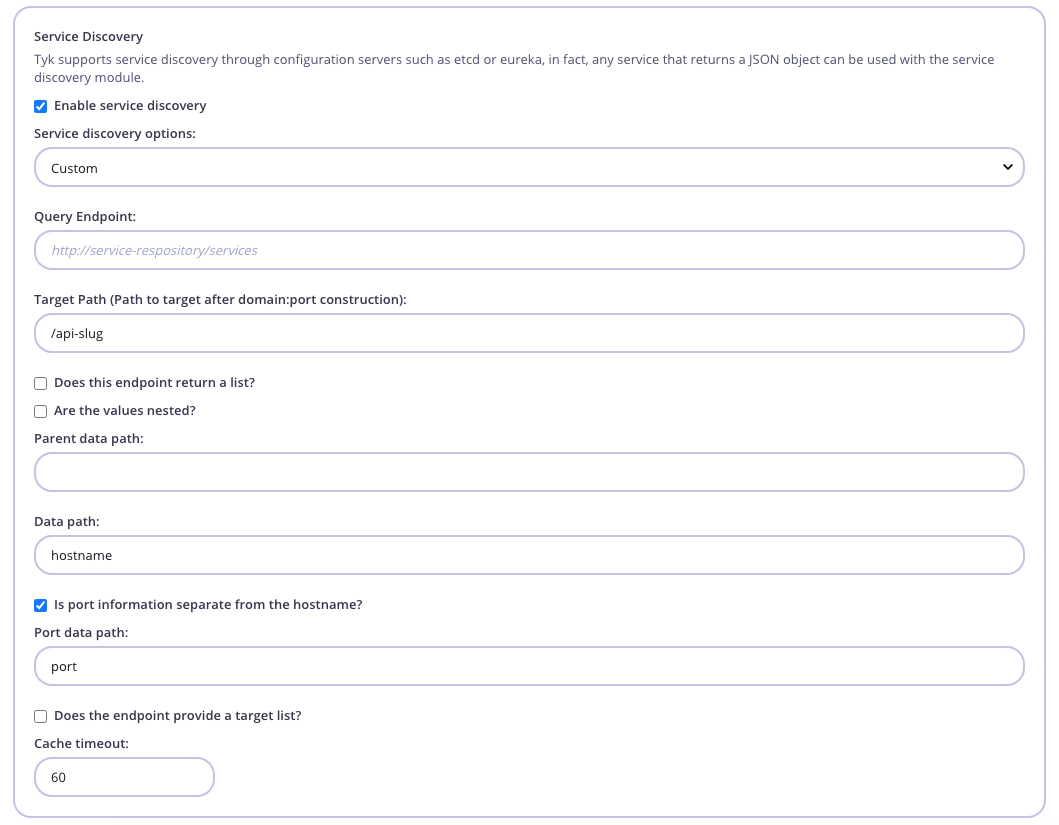
- Service discovery options: New Functionality
- Query endpoint: The endpoint to call, this would probably be your Consul, etcd or Eureka K/V store.
- Target path: Use this setting to set a target path to append to the discovered endpoint, since many SD services only provide host and port data, it is important to be able to target a specific resource on that host, setting this value will enable that.
- Data path: The namespace of the data path, so for example if your service responds with:
node.value.
- Are the values nested?: Sometimes the data you are retrieving is nested in another JSON object, e.g. this is how etcd responds with a JSON object as a value key:
checked, and use a combination of the data path and parent data path (below).
- Parent data path: This is the namespace of the where to find the nested value, in the above example, it would be
node.value. You would then change the data path setting to behostname, since this is where the hostname data resides in the JSON string. Tyk automatically assumes that the data_path in this case is in a string-encoded JSON object and will try to deserialise it.
- Port data path: In the above nested example, we can see that there is a separate
portvalue for the service in the nested JSON. In this case you can set the port data path value and Tyk will treat data path as the hostname and zip them together (this assumes that the hostname element does not end in a slash or resource identifier such as/widgets/).
port.
- Is port information separate from the hostname?: New Functionality
- Does the endpoint provide a target list?: If you are using load balancing, set this value to true and Tyk will treat the data path as a list and inject it into the target list of your API Definition.
- Cache timeout: Tyk caches target data from a discovery service, in order to make this dynamic you can set a cache value when the data expires and new data is loaded. Setting it too low will cause Tyk to call the SD service too often, setting it too high could mean that failures are not recovered from quickly enough.
Service Discovery Config: API Definition
Service discovery is configured on a per-API basis, and is set up in the API Object under theproxy section of your API Definition:
service_discovery.use_discovery_service: Set this totrueto enable the discovery module.service_discovery.query_endpoint: The endpoint to call, this would probably be your Consul, etcd or Eureka K/V store.service_discovery.data_path: The namespace of the data path so, for example, if your service responds with:
node.value.
service_discovery.use_nested_query: Sometimes the data you are retrieving is nested in another JSON object, e.g. this is how etcd responds with a JSON object as a value key:
use_nested_query to true, and use a combination of the data_path and parent_data_path (below)
service_discovery.parent_data_path: This is the namespace of the where to find the nested value, in the above example, it would benode.value. You would then change thedata_pathsetting to behostname, since this is where the host name data resides in the JSON string. Tyk automatically assumes that thedata_pathin this case is in a string-encoded JSON object and will try to deserialise it.
data_path namespace to that object in order to find the value.
service_discovery.port_data_path: In the above nested example, we can see that there is a separateportvalue for the service in the nested JSON. In this case you can set theport_data_pathvalue and Tyk will treatdata_pathas the hostname and zip them together (this assumes that the hostname element does not end in a slash or resource identifier such as/widgets/).
port_data_path would be port.
-
service_discovery.use_target_list: If you are using load balancing, set this value totrueand Tyk will treat the data path as a list and inject it into the target list of your API Definition. -
service_discovery.cache_timeout: Tyk caches target data from a discovery service, in order to make this dynamic you can set a cache value when the data expires and new data is loaded. Setting it too low will cause Tyk to call the SD service too often, setting it too high could mean that failures are not recovered from quickly enough. -
service_discovery.target_path: Use this setting to set a target path to append to the discovered endpoint, since many SD services only provide host and port data, it is important to be able to target a specific resource on that host, setting this value will enable that.
Service Discovery Examples
Mesosphere Example For integrating service discovery with Mesosphere, you can use the following configuration parameters:+json:
This configuration is a Tyk Community Contribution.
linkerd.yaml file, located in the config/ directory:
- Select your API from the System Management > APIs section and click Edit.
-
From the Core Settings tab, set the Target URL to the Linkerd HTTP server
host:portaddress. -
From the Endpoint Designer tab click Global Version Settings and enter
Custom-Headerin the Add this header: field and the value of the Linkerdapp-idin the Header value field. - Click Update to save your changes.