Introduction
API rate limiting is a technique that allows you to control the rate at which clients can consume your APIs and is one of the fundamental aspects of managing traffic to your services. It serves as a safeguard against abuse, overloading, and denial-of-service attacks by limiting the rate at which an API can be accessed. By implementing rate limiting, you can ensure fair usage, prevent resource exhaustion, and maintain system performance and stability, even under high traffic loads.What is rate limiting?
Rate limiting involves setting thresholds for the maximum number of requests that can be made within a specific time window, such as requests per second, per minute, or per day. Once a client exceeds the defined rate limit, subsequent requests may be delayed, throttled, or blocked until the rate limit resets or additional capacity becomes available.When might you want to use rate limiting?
Rate limiting may be used as an extra line of defense around attempted denial of service attacks. For instance, if you have load-tested your current system and established a performance threshold that you would not want to exceed to ensure system availability and/or performance then you may want to set a global rate limit as a defense to ensure it hasn’t exceeded. Rate limiting can also be used to ensure that one particular user or system accessing the API is not exceeding a determined rate. This makes sense in a scenario such as APIs which are associated with a monetization scheme where you may allow so many requests per second based on the tier in which that consumer is subscribed or paying for. Of course, there are plenty of other scenarios where applying a rate limit may be beneficial to your APIs and the systems that your APIs leverage behind the scenes.How does rate limiting work?
At a basic level, when rate limiting is in use, Tyk Gateway will compare the incoming request rate against the configured limit and will block requests that arrive at a higher rate. For example, let’s say you only want to allow a client to call the API a maximum of 10 times per minute. In this case, you would apply a rate limit to the API expressed as “10 requests per 60 seconds”. This means that the client will be able to successfully call the API up to 10 times within any 60 second interval (or window) and after for any further requests within that window, the user will get an HTTP 429 (Rate Limit Exceeded) error response stating the rate limit has been exceeded. Tyk’s rate limiter is configured using two variables:ratewhich is the maximum number of requests that will be permitted during the interval (window)perwhich is the length of the interval (window) in seconds
rate to 10 (requests) and per to 60 (seconds).
Rate Limit Response Headers
When rate limiting is active, API clients expect to seeX-RateLimit-* headers in the HTTP response to inform clients about their current limits.
Historically, Tyk populated these headers (X-RateLimit-Limit, X-RateLimit-Remaining, X-RateLimit-Reset) with quota data rather than rate limit data.
From Tyk 5.13.0, you can control the behavior of these headers using the rate_limit_response_headers configuration in your tyk.conf (or the equivalent environment variable):
rate_limits: the headers are only generated if a rate limit is configured; they are populated with rate limit data.quotas: the headers are only generated if a quota is configured; they are populated with quota data.
rate_limit_response_headers is not set, it defaults to quotas for backward compatibility.
Rate limiting scopes: API-level vs key-level
Rate limiting can be applied at different scopes to control API traffic effectively. This section covers the two primary scopes - API-level rate limiting and key-level rate limiting. Understanding the distinctions between these scopes will help you configure appropriate rate limiting policies based on your specific requirements.API-level rate limiting
API-level rate limiting aggregates the traffic coming into an API from all sources and ensures that the overall rate limit is not exceeded. Overwhelming an endpoint with traffic is an easy and efficient way to execute a denial of service attack. By using a API-level rate limit you can easily ensure that all incoming requests are within a specific limit so excess requests are rejected by Tyk and do not reach your service. You can calculate the rate limit to set by something as simple as having a good idea of the maximum number of requests you could expect from users of your API during a period. You could alternatively apply a more scientific and precise approach by considering the rate of requests your system can handle while still performing at a high-level. This limit may be easily determined with some performance testing of your service under load.Key-level rate limiting
Key-level rate limiting is more focused on controlling traffic from individual sources and making sure that users are staying within their prescribed limits. This approach to rate limiting allows you to configure a policy to rate limit in two ways:- key-level global limit limiting the rate of calls the user of a key can make to all APIs authorized by that key
- key-level per-API limit limiting the rate of calls the user of a key can make to specific individual APIs
- key-level per-endpoint limit limiting the rate of calls the user of a key can make to specific individual endpoints of an API
Which scope should I use?
The simplest way to figure out which level of rate limiting you’d like to apply can be determined by asking a few questions:- do you want to protect your service against denial of service attacks or overwhelming amounts of traffic from all users of the API? You’ll want to use an API-level rate limit!
- do you have a health endpoint that consumes very little resource on your service and can handle significantly more requests than your other endpoints? You’ll want to use an API-level per-endpoint rate limit!
- do you want to limit the number of requests a specific user can make to all APIs they have access to? You’ll want to use a key-level global rate limit!
- do you want to limit the number of requests a specific user can make to specific APIs they have access to? You’ll want to use a key-level per-API rate limit.
- do you want to limit the number of requests a specific user can make to a specific endpoint of an API they have access to? You’ll want to use a key-level per-endpoint rate limit.
Applying multiple rate limits
When multiple rate limits are configured, they are assessed in this order (if applied):- API-level per-endpoint rate limit (configured in API definition)
- API-level rate limit (configured in API definition)
- Key-level per-endpoint rate limit (configured in access key)
- Key-level per-API rate limit (configured in access key)
- Key-level global rate limit (configured in access key)
Combining multiple policies configuring rate limits
If more than one policy defining a rate limit is applied to a key then Tyk will apply the highest request rate permitted by any of the policies that defines a rate limit. Ifrate and per are configured in multiple policies applied to the same key then the Gateway will determine the effective rate limit configured for each policy and apply the highest to the key.
Given, policy A with rate set to 90 and per set to 30 seconds (3rps) and policy B with rate set to 100 and per set to 10 seconds (10rps). If both are applied to a key, Tyk will take the rate limit from policy B as it results in a higher effective request rate (10rps).
Prior to Tyk 5.4.0 there was a long-standing bug in the calculation of the effective rate limit applied to the key where Tyk would combine the highest
rate and highest per from the policies applied to the key, so for the example above the key would have rate set to 100 and per set to 30 giving an effective rate limit of 3.33rps. This has now been corrected.Rate limiting algorithms
Different rate limiting algorithms are employed to cater to varying requirements, use cases and gateway deployments. A one-size-fits-all approach may not be suitable, as APIs can have diverse traffic patterns, resource constraints, and service level objectives. Some algorithms are more suited to protecting the upstream service from overload whilst others are suitable for per-client limiting to manage and control fair access to a shared resource. Tyk offers the following rate limiting algorithms:- Distributed Rate Limiter: recommended for most use cases, implements the token bucket algorithm
- Redis Rate Limiter: implements the sliding window log algorithm
- Fixed Window Rate Limiter: implements the fixed window algorithm
Tyk supports selection of the rate limit algorithm at the Gateway level, so the same algorithm will be applied to all APIs.
It can be configured to switch dynamically between two algorithms depending on the request rate, as explained here.
Distributed Rate Limiter
The Distributed Rate Limiter (DRL) is the default rate limiting mechanism in Tyk Gateway. It is implemented using a token bucket implementation that does not use Redis. In effect, it divides the configured rate limit between the number of addressable gateway instances. The characteristics of DRL are:- a rate limit of 100 requests/min with 2 gateways yields 50 requests/min per gateway
- unreliable at low rate limits where requests are not fairly balanced
- if configured to return rate limits, the
X-RateLimit-Remainingresponse header will only reflect the current Gateway’s share of the limit, rather than the true global remaining limit across the cluster
Redis Rate Limiter
This algorithm implements a sliding window log algorithm and can be enabled via the enable_redis_rolling_limiter configuration option. The characteristics of the Redis Rate Limiter (RRL) are:- using Redis lets any gateway respect a cluster-wide rate limit (shared counter)
- a record of each request, including blocked requests that return
HTTP 429, is written to the sliding log in Redis - the log is constantly trimmed to the duration of the defined window
- requests are blocked if the count in the log exceeds the configured rate limit
HTTP 429
responses stop and traffic is resumed. This behavior is called spike arrest.
The complete request log is stored in Redis so resource usage when using this rate limiter is high.
This algorithm will use significant resources on Redis even when blocking requests, as it must
maintain the request log, mostly impacting CPU usage. Redis resource
usage increases with traffic therefore shorter per values are recommended to
limit the amount of data being stored in Redis.
If you wish to avoid spike arrest behavior but the DRL is not suitable, you might use the Fixed Window Rate Limiter algorithm.
You can configure Rate Limit Smoothing to manage the traffic spike, allowing time to increase upstream capacity if required.
The Redis Sentinel Rate Limiter reduces latency for clients, however increases resource usage on Redis and Tyk Gateway.
Rate Limit Smoothing
Rate Limit Smoothing is an optional mechanism of the RRL that dynamically adjusts the request rate limit based on the current traffic patterns. It helps in managing request spikes by gradually increasing or decreasing the rate limit instead of making abrupt changes or blocking requests excessively. This mechanism uses the concept of an intermediate current allowance (rate limit) that moves between an initial lower bound (threshold) and the maximum configured request rate (rate). As the request rate approaches the current
current allowance, Tyk will emit an event to notify you that smoothing has been triggered. When the event is emitted,
the current allowance will be increased by a defined increment (step). A hold-off counter (delay) must expire
before another event is emitted and the current allowance further increased. If the request rate exceeds the
current allowance then the rate limiter will block further requests, returning HTTP 429 as usual.
As the request rate falls following the spike, the current allowance will gradually reduce back to the lower bound (threshold).
Events are emitted and adjustments made to the current allowance based on the following calculations:
- when the request rate rises above
current allowance - (step * trigger), aRateLimitSmoothingUpevent is emitted and current allowance increases bystep. - when the request rate falls below
allowance - (step * (1 + trigger)), aRateLimitSmoothingDownevent is emitted and current allowance decreases bystep.
Configuring rate limit smoothing
When Redis Rate Limiter is in use, rate limit smoothing is configured with the following options within thesmoothing object alongside the standard rate and per parameters:
enabled(boolean) to enable or disable rate limit smoothingthresholdis the initial rate limit (current allowance) beyond which smoothing will be appliedstepis the increment by which the current allowance will be increased or decreased each time a smoothing event is emittedtriggeris a fraction (typically in the range 0.1-1.0) of thestepat which point a smoothing event will be emitted as the request rate approaches the current allowancedelayis a hold-off between smoothing events and controls how frequently the current allowance will step up or down (in seconds).
smoothing object within access keys and policies. For API-level rate limiting, this configuration is within the access_rights[*].limit object.
An example configuration would be as follows:
Redis Sentinel Rate Limiter
The Redis Sentinel Rate Limiter option will:- write a sentinel key into Redis when the request limit is reached
- use the sentinel key to block requests immediately for
perduration - requests, including blocked requests, are written to the sliding log in a background thread
per). Gateway and Redis
resource usage is increased with this option.
This option can be enabled using the following configuration option
enable_sentinel_rate_limiter.
To optimize performance, you may configure your rate limits with shorter
window duration values (per), as that will cause Redis to hold less
data at any given moment.
Performance can be improved by enabling the enable_non_transactional_rate_limiter. This leverages Redis Pipelining to enhance the performance of the Redis operations. Please consult the Redis documentation for more information.
Please consider the Fixed Window Rate Limiter algorithm as an alternative, if Redis performance is an issue.
Fixed Window Rate Limiter
The Fixed Window Rate Limiter will limit the number of requests in a particular window in time. Once the defined rate limit has been reached, the requests will be blocked for the remainder of the configured window duration. After the window expires, the counters restart and again allow requests through.- the implementation uses a single counter value in Redis
- the counter expires after every configured window (
per) duration.
rate in a window, the requests are processed without delay, until
the rate limit is reached and requests are blocked for the remainder of the
window duration.
When using this option, resource usage for rate limiting does not
increase with traffic. A simple counter with expiry is created for every
window and removed when the window elapses. Regardless of the traffic
received, Redis is not impacted in a negative way, resource usage remains
constant.
This algorithm can be enabled using the following configuration option enable_fixed_window_rate_limiter.
If you need spike arrest behavior, the Redis Rate Limiter should be used.
Dynamic algorithm selection based on request rate
The Distributed Rate Limiter (DRL) works by distributing the rate allowance equally among all gateways in the cluster. For example, with a rate limit of 1000 requests per second and 5 gateways, each gateway can handle 200 requests per second. This distribution allows for high performance as gateways do not need to synchronize counters for each request. DRL assumes an evenly load-balanced environment, which is typically achieved at a larger scale with sufficient requests. In scenarios with lower request rates, DRL may generate false positives for rate limits due to uneven distribution by the load balancer. For instance, with a rate of 10 requests per second across 5 gateways, each gateway would handle only 2 requests per second, making equal distribution unlikely. It’s possible to configure Tyk to switch automatically between the Distributed Rate Limiter and the Redis Rate Limiter by setting thedrl_threshold configuration.
This threshold value is used to dynamically switch the rate-limiting
algorithm based on the volume of requests. This option sets a
minimum number of requests per gateway that triggers the Redis Rate
Limiter. For example, if drl_threshold is set to 2, and there are 5
gateways, the DRL algorithm will be used if the rate limit exceeds 10
requests per second. If it is 10 or fewer, the system will fall back to
the Redis Rate Limiter.
See DRL Threshold for details on how to configure this feature.
Custom Rate Limiting
Different business models may require applying rate limits and quotas not only by credentials but also by other entities, such as per application, per developer, per organization, etc. For example, if an API Product is sold to a B2B customer, the quota of API calls is usually applied to all developers and their respective applications combined, in addition to a specific credential. To enable this, Tyk introduced support for custom rate limit keys in Tyk 5.3.0. This feature allows you to define custom patterns for rate limiting that go beyond the default credential-based approach.How Custom Rate Limiting Works
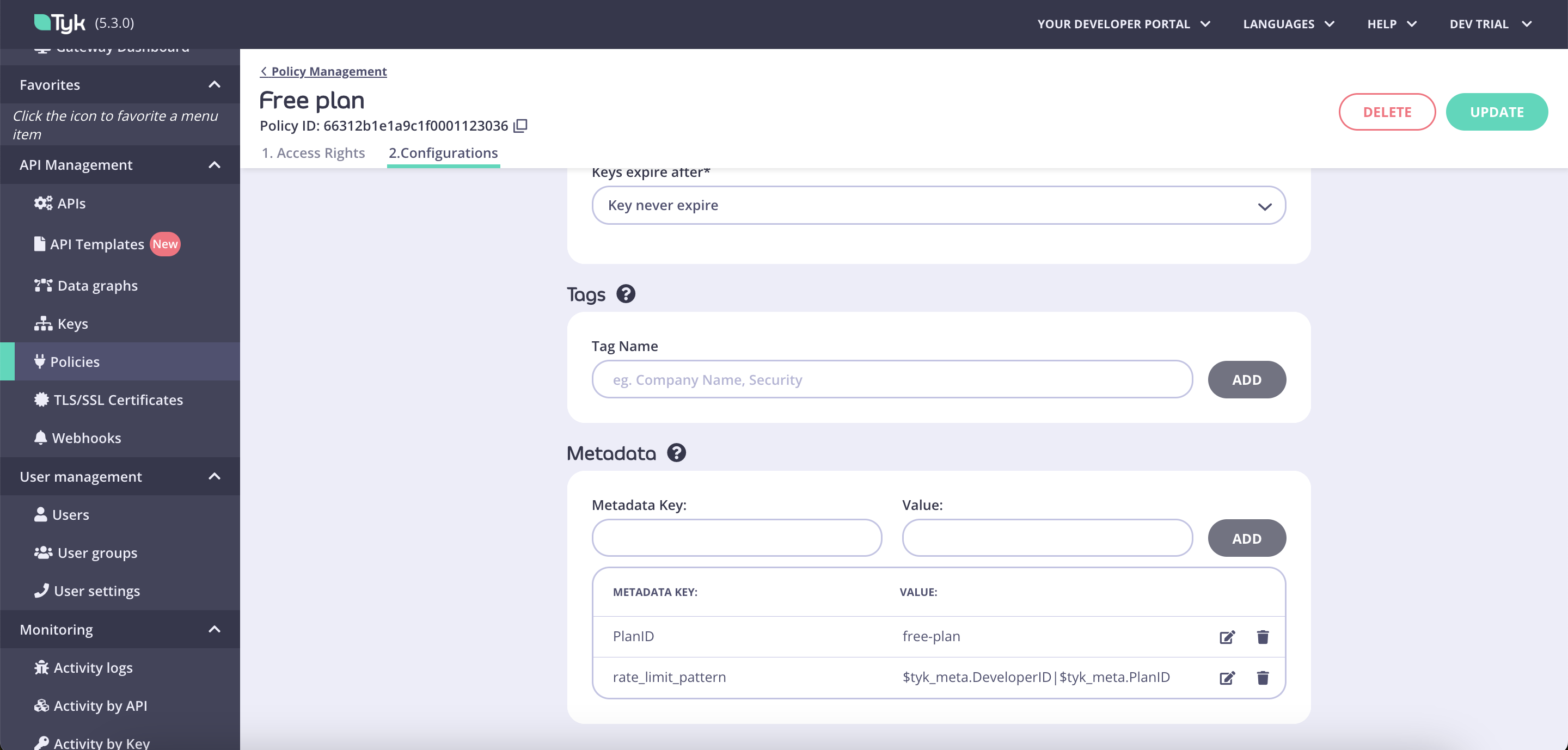
Custom rate limit keys are applied at a policy level. When a custom rate limit key is specified, quota, rate limit and throttling will be calculated against the specified value and not against a credential ID. To specify a custom rate limit key, add to a policy a new metadata field calledrate_limit_pattern. In the value field you can specify any value or expression that you want to use as a custom rate limit key for your APIs.
The rate_limit_pattern field supports:
- Referencing session metadata using
$tyk_meta.FIELD_NAMEsyntax - Concatenating multiple values together using the pipe operator (
|)
Configuring Custom Rate Limit Keys
Custom rate limit keys are configured in the Tyk Dashboard by adding a metadata field to your policy:- Navigate to your policy in the Tyk Dashboard
- Add a new metadata field called
rate_limit_pattern - Set the value to your desired pattern expression
DeveloperID and PlanID metadata fields are available in a session):
Important Considerations
Updating credential metadataThe custom rate limit key capability uses only metadata objects, such as credentials metadata available in a session. Therefore, if the
rate_limit_pattern relies on credentials metadata, this capability will work only if those values are present. If, after evaluating the rate_limit_pattern, its value is equal to an empty string, the rate limiter behavior defaults to rate limiting by credential IDs.Advanced Custom Rate Limiting
As mentioned above, we can easily configure custom rate limit keys for simple scenarios that do not require awareness of the request context. When more complex logic or integration with external services is required to determine the rate-limiting key, for example when you want to rate limit per requester IP address, a custom authentication plugin can be used to identify and generate the rate limiter key. We use an authentication plugin because it lets us modify the session object.This mechanism works only for authenticated APIs, since the authentication plugin is not invoked for unauthenticated (keyless) APIs.
Example: Rate Limiting by IP Address
The example below shows an IP based rate limiter implemented as a custom Go plugin for a Tyk OAS API. Note that the Go library function to obtain the API definition is specific to Tyk OAS APIs, so you would need to modify the plugin for a Tyk Classic API.- It extracts the client’s IP address from the request
- Creates a session object with rate limiting parameters (2 requests per 5 seconds)
- Sets a custom
rate_limit_patternin the session’s metadata to use the IP as the rate limiting key - Stores this session in Tyk’s session store
How to Use This
- Build and Deploy plugin: Build the plugin and deploy it to your Tyk Gateway. Refer to the Go Plugin Development Guide for instructions on building and deploying Go plugins.
- Configure your API: Create an authenticated API and set up your API to use the custom authentication plugin. Note that you will need to select the multiple authentication method to invoke both the plugin and your chosen auth method.
- Test your implementation: Make requests to your API and verify that rate limiting is applied based on client IP addresses.
rate_limit_pattern to use any value you want as the rate limiting key, such as:
- A specific header value:
request.Header.Get("X-Custom-ID") - A combination of values:
userID + "-" + deviceID - A value extracted from the request body or JWT claims
Rate Limiting Layers
You can protect your upstream services from being flooded with requests by configuring rate limiting in Tyk Gateway. Rate limits in Tyk are configured using two parameters: allowrate requests in any per time period (given in seconds).
As explained in the Rate Limiting Concepts section, Tyk supports configuration of rate limits at both the API-Level and Key-Level for different use cases.
The API-Level rate limit takes precedence over Key-Level, if both are configured for a given API, since this is intended to protect your upstream service from becoming overloaded. The Key-Level rate limits provide more granular control for managing access by your API clients.
Configuring the rate limiter at the API-Level
If you want to protect your service with an absolute limit on the rate of requests, you can configure an API-level rate limit. You can do this from the API Designer in Tyk Dashboard as follows:- Navigate to the API for which you want to set the rate limit
- From the Core Settings tab, navigate to the Rate Limiting and Quotas section
- Ensure that Disable rate limiting is not selected
- Enter in your Rate and Per (seconds) values
- Save/Update your changes
HTTP 429 Too Many Requests error.
Check out the following video to see this being done.
Configuring the rate limiter at the Key-Level
If you want to restrict an API client to a certain rate of requests to your APIs, you can configure a Key-Level rate limit via a Policy. The allowance that you configure in the policy will be consumed by any requests made to APIs using a key generated from the policy. Thus, if a policy grants access to three APIs withrate=15 per=60 then a client using a key generated from that policy will be able to make a total of 15 requests - to any combination of those APIs - in any 60 second period before receiving the HTTP 429 Too Many Requests error.
It is assumed that the APIs being protected with a rate limit are using the auth token client authentication method and policies have already been created.
- Navigate to the Tyk policy for which you want to set the rate limit
- Ensure that API(s) that you want to apply rate limits to are selected
- Under Global Limits and Quota, make sure that Disable rate limiting is not selected and enter your Rate and Per (seconds) values
- Save/Update the policy
Setting up a Key-Level Per-API rate limit
If you want to restrict API clients to a certain rate of requests for a specific API you will also configure the rate limiter via the security policy. However this time you’ll assign per-API limits. The allowance that you configure in the policy will be consumed by any requests made to that specific API using a key generated from that policy. Thus, if a policy grants access to an API withrate=5 per=60 then three clients using keys generated from that policy will each independently be able to make 5 requests in any 60 second period before receiving the HTTP 429 Too Many Requests error.
It is assumed that the APIs being protected with a rate limit are using the auth token client authentication method and policies have already been created.
- Navigate to the Tyk policy for which you want to set the rate limit
- Ensure that API that you want to apply rate limits to is selected
- Under API Access, turn on Set per API Limits and Quota
- You may be prompted with “Are you sure you want to disable partitioning for this policy?”. Click CONFIRM to proceed
- Under Rate Limiting, make sure that Disable rate limiting is not selected and enter your Rate and Per (seconds) values
- Save/Update the policy
Setting up a key-level per-endpoint rate limit
To restrict the request rate for specific API clients on particular endpoints, you can use the security policy to assign per-endpoint rate limits. These limits are set within the policy and will be #enforced for any requests made to that endpoint by clients using keys generated from that policy. Each key will have its own independent rate limit allowance. For example, if a policy grants access to an endpoint with a rate limit of 5 requests per 60 seconds, each client with a key from that policy can make 5 requests to the endpoint in any 60-second period. Once the limit is reached, the client will receive an HTTP429 Too Many Requests error.
If no per-endpoint rate limit is defined, the endpoint will inherit the key-level per-API rate limit or the global rate limit, depending on what is configured.
The following assumptions are made:
- The ignore authentication middleware should not be enabled for the relevant endpoints.
- If path-based permissions are configured, they must grant access to these endpoints for keys generated from the policies.
- Navigate to the Tyk policy for which you want to set the rate limit
- Ensure that API that you want to apply rate limits to is selected
- Under API Access -> Set endpoint-level usage limits click on Add Rate Limit to configure the rate limit. You will need to provide the rate limit and the endpoint path and method.
- Save/Update the policy
Setting Rate Limits in the Tyk Community Edition Gateway (CE)
Configuring the rate limiter at the (Global) API-Level
Using theglobal_rate_limit field in the API definition you can specify the API-level rate limit in the following format: {"rate": 10, "per": 60}.
An equivalent example using Tyk Operator is given below:
Configuring the rate limiter on the session object
All actions on the session object must be done via the Gateway API.-
Ensure that
allowanceandrateare set to the same value: this should be number of requests to be allowed in a time period, so if you wanted 100 requests every second, set this value to 100. -
Ensure that
peris set to the time limit. Again, as in the above example, if you wanted 100 requests per second, set this value to 1. If you wanted 100 requests per 5 seconds, set this value to 5.
Can I disable the rate limiter?
Yes, the rate limiter can be disabled for an API Definition by selecting Disable Rate Limits in the API Designer, or by setting the value ofdisable_rate_limit to true in your API definition.
Alternatively, you could also set the values of Rate and Per (Seconds) to be 0 in the API Designer.
Disabling the rate limiter at the API-Level does not disable rate limiting at the Key-Level. Tyk will enforce the Key-Level rate limit even if the API-Level limit is not set.
Can I set rate limits by IP address?
Not yet, though IP-based rate limiting is possible using custom pre-processor middleware JavaScript that generates tokens based on IP addresses. See our Middleware Scripting Guide for more details.Rate Limiting by API
Tyk Classic API Definition
The per-endpoint rate limit middleware allows you to enforce rate limits on specific endpoints. This middleware is configured in the Tyk Classic API Definition, either via the Tyk Dashboard API or in the API Designer. To enable the middleware, add a newrate_limit object to the extended_paths section of your API definition.
The rate_limit object has the following configuration:
path: the endpoint pathmethod: the endpoint HTTP methodenabled: boolean to enable or disable the rate limitrate: the maximum number of requests that will be permitted during the interval (window)per: the length of the interval (window) in seconds
rate_limit objects.
Simple endpoint rate limit
For example:GET requests to the /anything endpoint, limiting requests to 60 per
second.
Advanced endpoint rate limit
For more complex scenarios, you can configure rate limits for multiple paths. The order of evaluation matches the order defined in therate_limit array. For example, if you wanted to limit the rate of
POST requests to your API allowing a higher rate to one specific
endpoint you could configure the API definition as follows:
POST requests to /user/login
to 100 requests per second (rps). Any other POST request matching the
regex pattern /.* will be limited to 60 requests per second. The order
of evaluation ensures that the specific /user/login endpoint is matched
and evaluated before the regex pattern.
The per-endpoint rate limit middleware allows you to enforce rate limits on specific endpoints. This middleware is configured in the Tyk OAS API Definition, either via the Tyk Dashboard API or in the API Designer.
If you’re using the legacy Tyk Classic APIs, then check out the Tyk Classic page.
Tyk OAS API Definition
The design of the Tyk OAS API Definition takes advantage of theoperationId defined in the OpenAPI Document that declares both the path
and method for which the middleware should be added. Endpoint paths
entries (and the associated operationId) can contain wildcards in the
form of any string bracketed by curly braces, for example
/status/{code}. These wildcards are so they are human-readable and do
not translate to variable names. Under the hood, a wildcard translates to
the “match everything” regex of: (.*).
The rate limit middleware (rateLimit) can be added to the operations section of the
Tyk OAS Extension (x-tyk-api-gateway) in your Tyk OAS API Definition
for the appropriate operationId (as configured in the paths section
of your OpenAPI Document).
The rateLimit object has the following configuration:
enabled: enable the middleware for the endpointrate: the maximum number of requests that will be permitted during the interval (window)per: the length of the interval (window) in time duration notation (e.g. 10s)
Simple endpoint rate limit
For example:GET /status/200 endpoint, limiting requests to 60 per second.
The configuration above is a complete and valid Tyk OAS API Definition
that you can import into Tyk to try out the Per-endpoint Rate Limiter
middleware.
Advanced endpoint rate limit
For more complex scenarios, you can configure rate limits for multiple paths. The order of evaluation matches the order that endpoints are defined in thepaths section of the OpenAPI description. For example,
if you wanted to limit the rate of POST requests to your API allowing a
higher rate to one specific endpoint you could configure the API
definition as follows:
POST /user/login
endpoint to 100 requests per second (rps). Any other POST request to an
endpoint path that matches the regex pattern /{any} will be limited to
60 rps. The order of evaluation ensures that the specific POST /user/login endpoint is matched and evaluated before the regex pattern.
The configuration above is a complete and valid Tyk OAS API Definition
that you can import into Tyk to try out the Per-endpoint Rate Limiter
middleware.
Configuring the middleware in the API Designer
Configuring per-endpoint rate limits for your API endpoints is easy when using the API Designer in the Tyk Dashboard, simply follow these steps:-
Add an endpoint
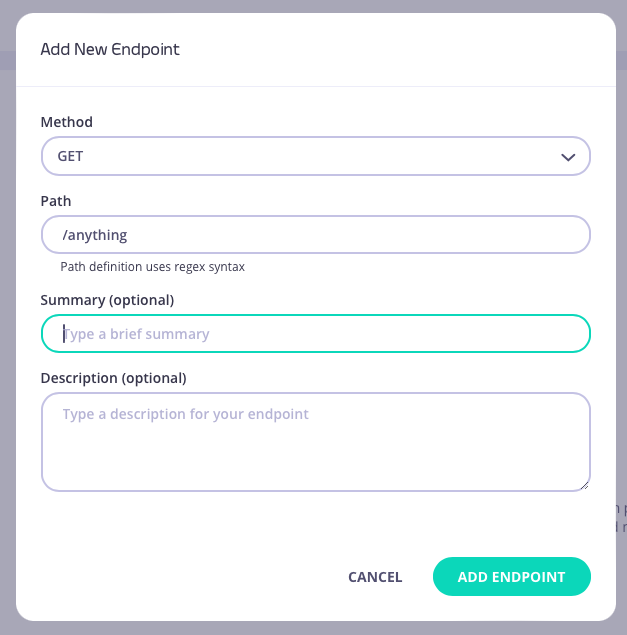
From the API Designer add an endpoint that matches the path and method to which you want to apply the middleware.
-
Select the Rate Limit middleware
Select ADD MIDDLEWARE and choose Rate Limit from the Add Middleware screen.
-
Configure the middleware
You must provide the path to the compiled plugin and the name of the Go function that should be invoked by Tyk Gateway when the middleware is triggered.
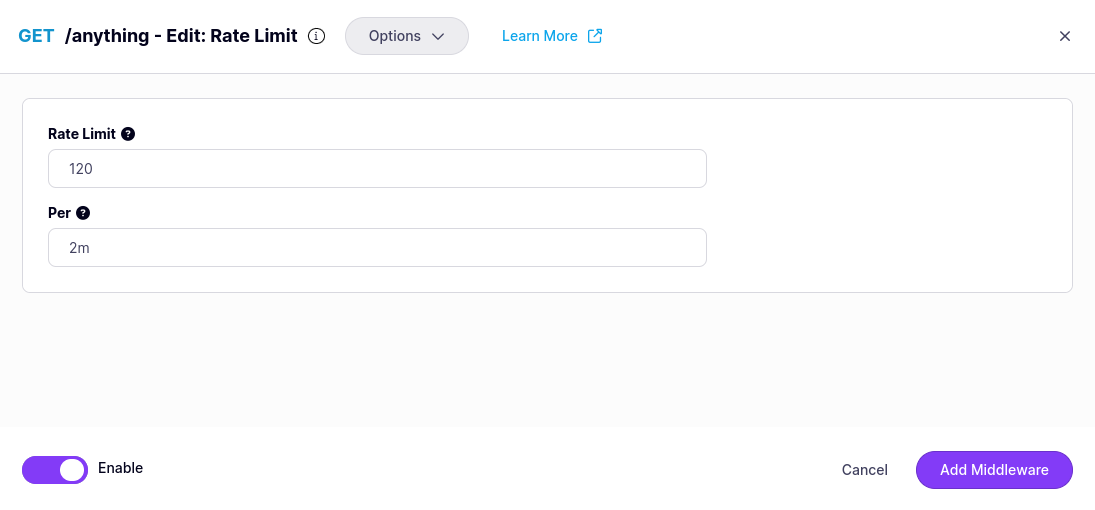
- Save the API Select ADD MIDDLEWARE to save the middleware configuration. Remember to select SAVE API to apply the changes.
Rate Limiting with Tyk Streams
A rate limit is a strategy for limiting the usage of a shared resource across parallel components in a Tyk Streams instance, or potentially across multiple instances. They are configured as a resource:rate_limit for specifying a rate limit resource to use. For example, if we wanted to use our foobar rate limit with a HTTP request:
Local
The local rate limit is a simple X every Y type rate limit that can be shared across any number of components within the pipeline but does not support distributed rate limits across multiple running instances of Tyk Streams.intDefault:
1000
interval
The time window to limit requests by.
Type: stringDefault:
"1s"