Performance Expectations
Tyk is a high-performance API Gateway written in Go, capable of handling significant loads. Our official benchmarks demonstrate that Tyk can handle over 80,000 requests per second, and over 54,000 requests per second with a full feature set (including authentication, rate limiting, and analytics) enabled.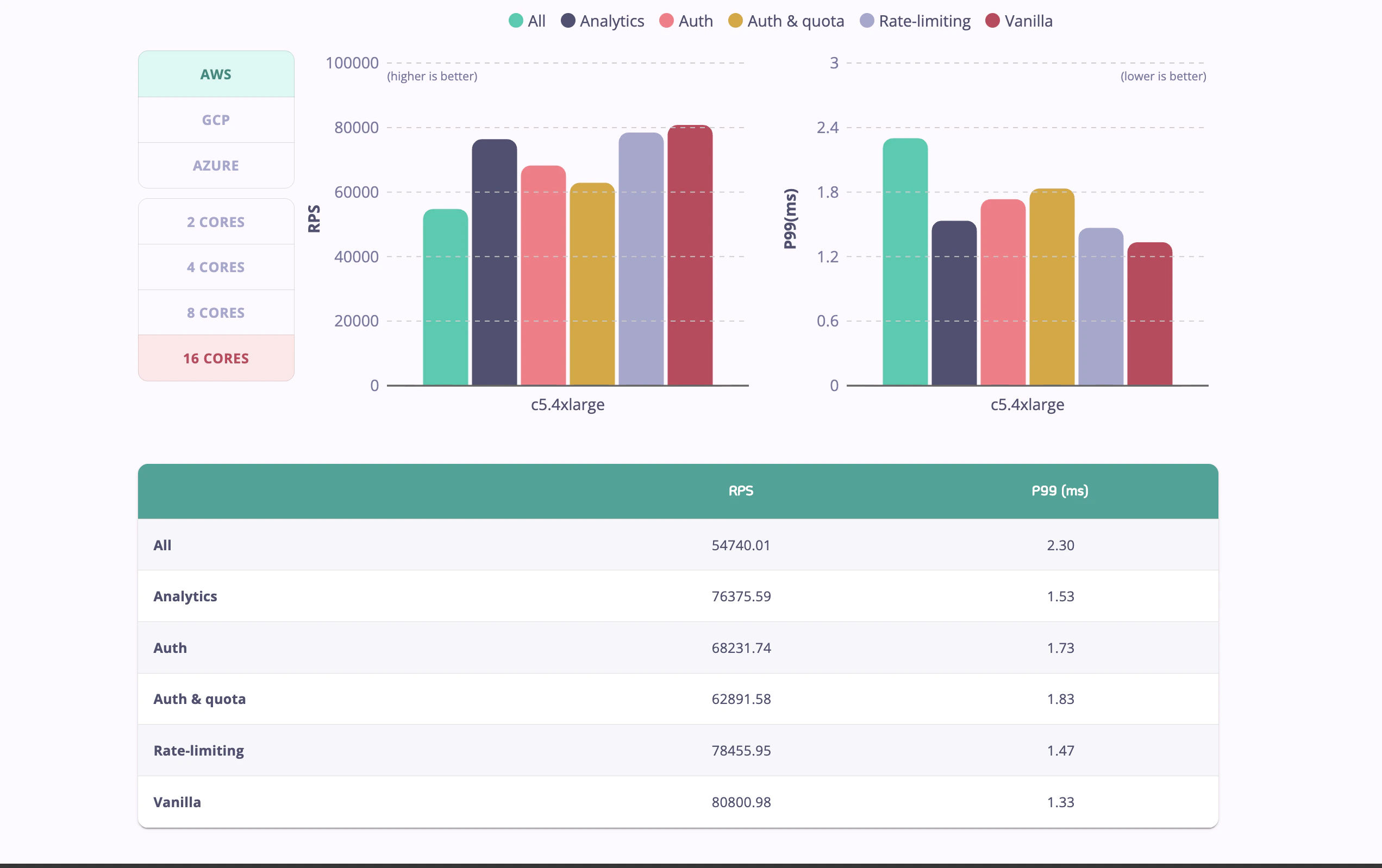
- Tyk Performance Benchmarks: Detailed analysis of Tyk’s performance across various scenarios.
- Tyk Performance Tests Repository: Replicate our performance tests yourself using our open-source testing framework.
- Performance Tuning Your Gateway: A step-by-step guide to fine-tuning your Gateway for maximum performance.
- Manual Performance Testing on AWS: Best practices for setting up and running manual performance tests on AWS to ensure your Gateway is optimized.
Change all the shared secrets
Ensure that these are changed before deploying to production. The main secrets to consider are:tyk.conf:
secretnode_secret
tyk_analytics.conf:
admin_secretshared_node_secrettyp_api_config.secret
secret and DB tyk_api_config.secret must match
GW node_secret and DB shared_node_secret must match
Use the public/private key message security!
Tyk makes use of public-key message verification for messages that are sent from the Dashboard to the Gateways, these messages can include:- Zeroconfig Dashboard auto-discovery details
- Cluster reload messages
- Cluster configuration getters/setters for individual Gateways in a cluster
Change your Control Port
To secure your Tyk installation, you can configure the following settings in your tyk.conf:control_api_hostname - Set the hostname to which you want to bind the REST API.
control_api_port - This allows you to run the Gateway Control API on a separate port, and protect it behind a firewall if needed.
If you change these values, you need to update the equivalent fields in the dashboard conf file tyk_analytics.conf: tyk_api_config.Host and tyk_api_config.Port
Recommended Topology
Keep Redis and your persistent database (MongoDB or PostgreSQL) on dedicated infrastructure, separate from the systems running Tyk Gateway and Tyk Dashboard. Both Redis and Tyk Gateway are memory-intensive and CPU-intensive; running them on the same host creates resource contention. The recommended production topology is:- Two or more Tyk Gateways, load balanced, each on a separate machine.
- A separate Redis instance using Redis Sentinel for high availability, or Redis Cluster for horizontal scalability.
- A separate MongoDB or PostgreSQL cluster.
- One Tyk Dashboard node on a separate machine.
- One Tyk Pump node on a separate machine.
Connecting Multiple Gateways to a Single Dashboard
Please note that, for a Self-Managed installation, the number of gateway nodes you may register with your dashboard concurrently will be subject to the terms of your license. Each gateway node must be configured in the same way, with the exception being if you want to shard your gateways. Each gateway node in the cluster will need connectivity to the same Redis server and persistent database.Use a Consistent License Across Dashboard Instances
When you run more than one Tyk Dashboard instance against the same Redis and database backend, every instance must use the same license key. This matters most during a rolling or blue-green upgrade, or while updating a license, because old and new instances can run side by side with different keys. A Tyk Dashboard license defines the pool of gateway nodes that the Dashboard is allowed to register, and this node information is shared through Redis. When two instances connect to the same Redis with different licenses, one Dashboard can reject gateways that were registered against the other license. Affected gateways fail to register with an HTTP 404 response, and the Dashboard logslevel=error msg="GetSpareNode returned node not allowed by this dashboard's license". Gateways that cannot register lead to 404 responses and prevent API creation.
To avoid this, apply any license change to every Dashboard instance that shares the same backend. See the Upgrading Guide for upgrade guidance and Troubleshooting to resolve the error.
Other Dashboard Security Considerations
In addition to changing the default secrets (see Change all the shared secrets) if you change the Control API port (see Change your Control Port), you also need to change the connection string settings in yourtyk_analytics.conf file.
Ensure you are matching only the URL paths that you want to match
We recommend that you configure Tyk Gateway to use exact URL path matching and to enforce strict route matching to avoid accidentally invoking your unsecured/health endpoint when a request is made to /customer/{customer_id}/account/health…
Unless you want to make use of Tyk’s flexible listen path and endpoint path matching modes and understand the need to configure patterns carefully, you should enable TYK_GW_HTTPSERVEROPTIONS_ENABLESTRICTROUTES, TYK_GW_HTTPSERVEROPTIONS_ENABLEPATHPREFIXMATCHING and TYK_GW_HTTPSERVEROPTIONS_ENABLEPATHSUFFIXMATCHING.
Health checks are expensive
To keep real-time health-check data and make it available to the Health-check API, Tyk needs to record information for every request, in a rolling window - this is an expensive operation and can limit throughput - you have two options: switch it off, or get a box with more cores.Selecting the appropriate log level
Tyk provides multiple log levels: error, warn, info, debug. Setting higher log levels consumes more computing resources and would have an impact on the Tyk component. Tyk installations default to log level info unless modified by config files or environment variables. It is recommended to set to debug only for the duration of troubleshooting as it adds heavier resource overheads. In high performance use cases for Tyk Gateway, consider setting a log level lower than info to improve overall throughput.Use the optimization settings
The below settings will ensure connections are effectively re-used, removes a transaction from the middleware run that enforces org-level rules, enables the new rate limiter (by disabling sentinel rate limiter) and sets Tyk up to use an in-memory cache for session-state data to save a round-trip to Redis for some other transactions. Most of the changes below should be already in yourtyk.conf by default:
max_idle_connections_per_host option, was capped at 100. From v2.7 you have been able to set it to any value.
max_idle_connections_per_host limits the number of keep-alive connections between clients and Tyk. If you set this value too low, then Tyk will not re-use connections and you will have to open a lot of new connections to your upstream.
If you set this value too high, you may encounter issues when slow clients occupy your connection and you may reach OS limits.
You can calculate the right value using a straightforward formula:
If the latency between Tyk and your Upstream is around 50ms, then a single connection can handle 1s / 50ms = 20 requests. So if you plan to handle 2000 requests per second using Tyk, the size of your connection pool should be at least 2000 / 20 = 100. For example, on low-latency environments (like 5ms), a connection pool of 100 connections will be enough for 20k RPS.
Protect Redis from overgrowing
Please read carefully through this doc to make an aware decision about the expiration of your keys in Redis, after which they will be removed from Redis. If you don’t set the lifetime, a zero default means that keys will stay in Redis until you manually delete them, which is no issue if you have a process outside Tyk Gateway to handle it. If you don’t - and especially in scenarios that your flow creates many keys or access tokens for every user or even per call - your Redis can quickly get cluttered with obsolete tokens and eventually affect the performance of the Tyk Gateway.Analytics Optimizations
If using a Redis cluster under high load it is recommended that analytics are distributed among the Redis shards. This can be configured by setting the analytics_config.enable_multiple_analytics_keys parameter to true. Furthermore, analytics can also be disabled for an API using the do_not_track configuration parameter. Alternatively, tracking for analytics can be disabled for selected endpoints using the do not track endpoint plugin.Protobuf Serialisation
In Tyk Gateway, using protobuf serialisation, instead of msgpack can increase performance for sending and processing analytics.Note: protobuf is not currently supported in MDCB deployment. If using Tyk Cloud platform under high load, it is also recommended that analytics are stored within a local region. This means that a local Tyk Pump instance can send the analytics to a localised data sink, such as PostgreSQL or MongoDB (no need for the hybrid pump). This can reduce traffic costs since your analytics would not be sent across regions.
Use the right hardware
Tyk is CPU-bound: you will get exponentially better performance the more cores you throw at Tyk - it’s that simple. Tyk will automatically spread itself across all cores to handle traffic, but if expensive operations like health-checks are enabled, then those can cause keyspace contention, so again, while it helps, health-checks do throttle throughput.Resource limits
Make sure your host operating system has resource limits set to handle an appropriate number of connections. You can increase the maximum number of files available to the kernel by modifying/etc/sysctl.conf.
fs.file-max=160000 will consume a maximum of 160MB ram.
The changes will apply after a system reboot, but if you do not wish to reboot quite yet, you can apply the change for the current session using echo 160000 > /proc/sys/fs/file-max.
File Handles / File Descriptors
Now we need to configure the file handles available to your Tyk services.systemd
Override yoursystemd unit files for each of the Tyk services using systemctl edit {service_name}.
- Gateway
systemctl edit tyk-gateway.service - Dashboard
systemctl edit tyk-dashboard.service - Pump
systemctl edit tyk-pump.service - Multi Data-Center Bridge
systemctl edit tyk-sink.service
LimitNOFILE=80000 to the [Service] directive as follows:
Docker
You may set ulimits in a container using the--ulimit option. See Docker documentation for detail on setting ulimits
If you are not using systemd or Docker, please consult your Operating System documentation for controlling the number of File Descriptors available for your process.
File modification at runtime
Understanding what files are created or modified by the Dashboard and Gateway during runtime can be important if you are running infrastructure orchestration systems such as Puppet, which may erroneously see such changes as problems that need correcting.- Both the Gateway and Dashboard will create a default configuration file if one is not found.
- Dashboard will write the license into the configuration file if you add it via the UI.
- From Tyk v2.3 onwards it has been possible for a Dashboard to remotely change the config of a Gateway. This will cause the Gateway’s configuration file to update.